 影刀RPA进阶教程跨平台数据同步方案Excel飞书数据库之间的一键互通你的数据散落在三个地方电商后台导出的数据在Excel里团队协作的数据在飞书多维表格里历史归档的数据在SQLite数据库里每次做分析你要手动从三个地方导出、拼接、去重。如果这三个地方的数据能自动互相同步——你的工作就少了80%。这篇文章讲的就是数据跨平台同步这件事。同步的本质是什么跨平台数据同步本质上是三个动作的循环读取源A → 转换格式 → 写入目标B所有同步方案都是这个结构的变体。区别只在于源是什么Excel、飞书、数据库、API目标是什么同上转换逻辑有多复杂直接复制、字段映射、计算衍生字段同步一Excel ↔ SQLite这是最常见的同步场景——采集数据到Excel需要入库持久化。Excel → SQLite拼多多店群自动化报活动上架importpandasaspdimportsqlite3defexcel_to_sqlite(excel_path,db_path,table_name,modereplace):将Excel数据同步到SQLitedfpd.read_excel(excel_path)connsqlite3.connect(db_path)ifmodereplace:df.to_sql(table_name,conn,if_existsreplace,indexFalse)elifmodeappend:df.to_sql(table_name,conn,if_existsappend,indexFalse)elifmodeupsert:# 先建临时表再用INSERT OR REPLACEdf.to_sql(f{table_name}_tmp,conn,if_existsreplace,indexFalse)conn.execute(fDELETE FROM{table_name}WHERE 日期 IN (SELECT 日期 FROM{table_name}_tmp))conn.execute(fINSERT INTO{table_name}SELECT * FROM{table_name}_tmp)conn.execute(fDROP TABLE{table_name}_tmp)conn.commit()conn.close()print(f同步完成{len(df)}条 →{table_name})SQLite → Exceldefsqlite_to_excel(db_path,table_name,excel_path,queryNone):将SQLite数据导出到Excelconnsqlite3.connect(db_path)ifquery:dfpd.read_sql_query(query,conn)else: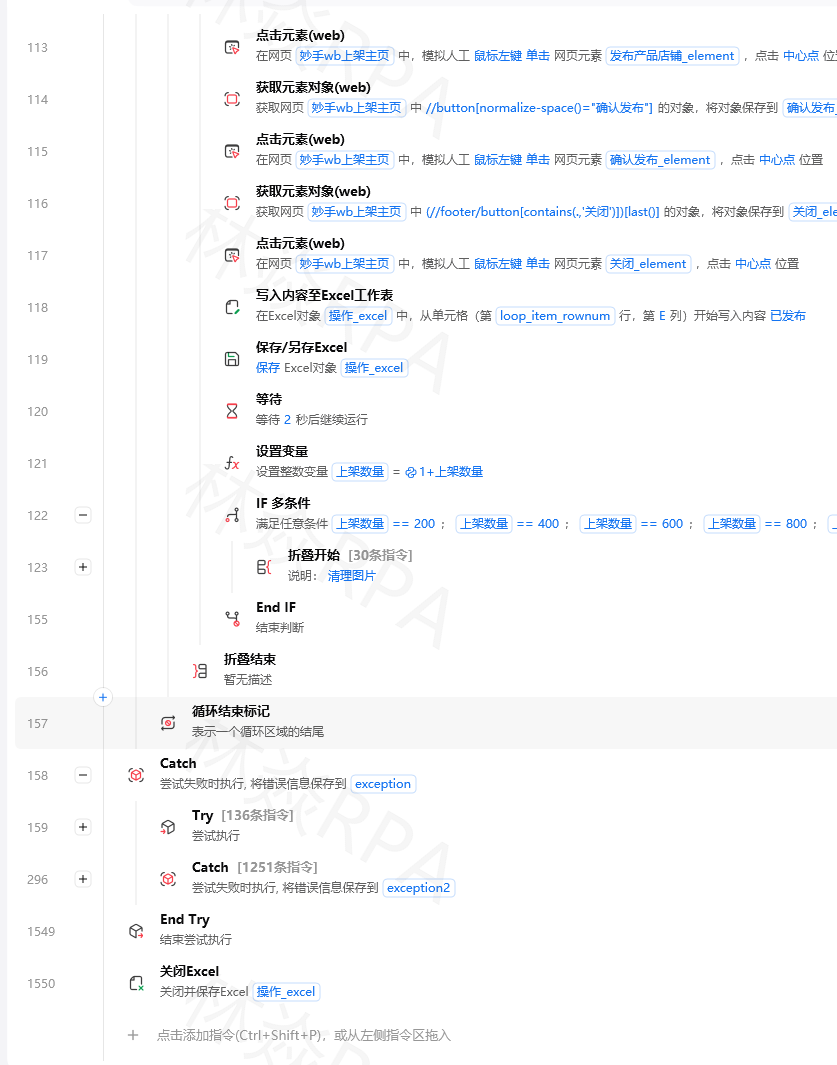dfpd.read_sql_query(fSELECT * FROM{table_name},conn)df.to_excel(excel_path,indexFalse)conn.close()print(f导出完成{len(df)}条 →{excel_path})增量同步只同步新增的数据全量同步简单但每次都重写整个表。数据多了以后很慢。增量同步只处理新增和变更的数据defincremental_sync(excel_path,db_path,table_name,key_columnid):增量同步只同步Excel中新增和变更的记录df_newpd.read_excel(excel_path)connsqlite3.connect(db_path)# 获取数据库中已有的ID集合existing_idsset(pd.read_sql_query(fSELECT{key_column}FROM{table_name},conn)[key_column].values)# 分离新增和变更new_idsset(df_new[key_column].values)to_insertdf_new[~df_new[key_column].isin(existing_ids)]to_updatedf_new[df_new[key_column].isin(existing_ids)]# 插入新增to_insert.to_sql(table_name,conn,if_existsappend,indexFalse)# 更新已有用temp table updateiflen(to_update)0:to_update.to_sql(_tmp_update,conn,if_existsreplace,indexFalse)# 构建UPDATE语句...这里简化处理实际按需写conn.commit()conn.close()print(f增量同步新增{len(to_insert)}更新{len(to_update)})同步二飞书多维表格 ↔ Excel飞书多维表格 → Excel读取飞书数据到本地importrequestsimportpandasaspddeffeishu_bitable_to_excel(app_token,table_id,token,excel_path):读取飞书多维表格并导出为Excelheaders{Authorization:fBearer{token}}all_records[]page_tokenNonewhileTrue:urlfhttps://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/recordsparams{page_size:500}ifpage_token:params[page_token]page_token 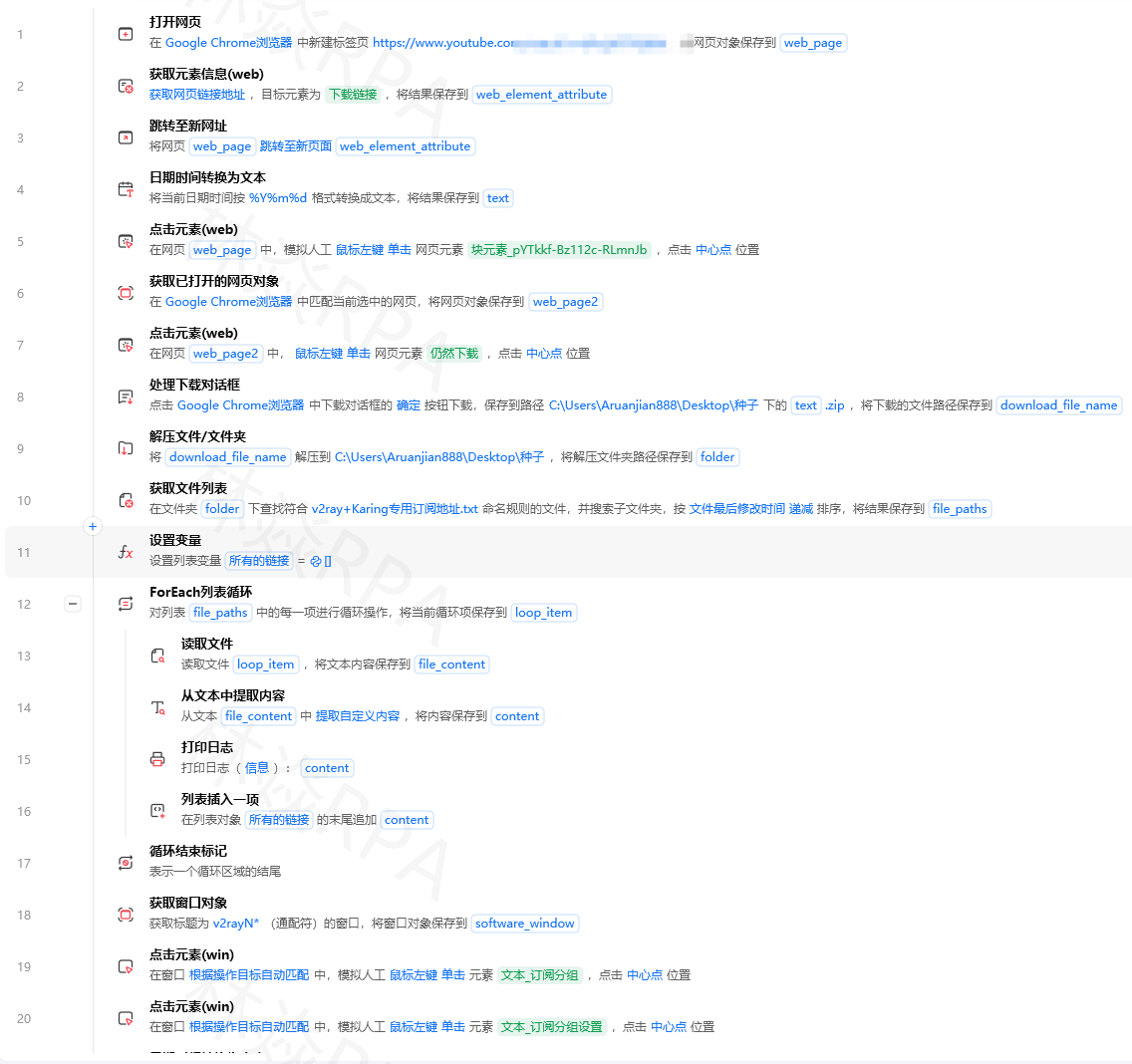resprequests.get(url,headersheaders,paramsparams)dataresp.json()forrecordindata.get(data,{}).get(items,[]):all_records.append(record[fields])ifnotdata.get(data,{}).get(has_more):breakpage_tokendata[data][page_token]dfpd.DataFrame(all_records)df.to_excel(excel_path,indexFalse)print(f飞书 → Excel{len(df)}条)Excel → 飞书多维表格参考上一篇飞书文档的文章用batch_create接口写入。定时双向同步策略每天 08:00飞书 → 本地SQLite拉取最新线上数据 每天 20:00本地SQLite → 飞书推送今日采集结果避免同一时间双向同步——可能导致数据冲突。同步三Excel ↔ CSV简单但高频的场景。Excel → CSVdfpd.read_excel(data.xlsx)df.to_csv(data.csv,indexFalse,encodingutf-8-sig)CSV → Exceldfpd.read_csv(data.csv)df.to_excel(data.xlsx,indexFalse)批量转换importglobdefbatch_csv_to_excel(folder,output_folderNone):把一个文件夹里的所有CSV转成xlsxifoutput_folderisNone:output_folderfolder csv_filesglob.glob(os.path.join(folder,*.csv))forcsv_fileincsv_files:dfpd.read_csv(csv_file)basenameos.path.splitext(os.path.basename(csv_file))[0]excel_pathos.path.join(output_folder,f{basename}.xlsx)df.to_excel(excel_path,indexFalse)print(f✓{basename})print(f批量转换完成{len(csv_files)}个文件)同步四多个Excel文件合并同步你的数据可能来自不同部门每个部门一个Excel。相同结构合并defmerge_excel_files(folder,output_path):合并同一文件夹下所有xlsx文件结构相同all_dfs[]forfileinos.listdir(folder):iffile.endswith(.xlsx)andnotfile.startswith(~):file_pathos.path.join(folder,file)dfpd.read_excel(file_path)df[来源文件]file# 加个标记列all_dfs.append(df)mergedpd.concat(all_dfs,ignore_indexTrue)merged.to_excel(output_path,indexFalse)print(f合并完成{len(all_dfs)}个文件 →{len(merged)}行)不同结构但有共同字段defmerge_by_common_field(folder,common_field,output_path):按共同字段合并不同结构的ExcelmergedNoneforfileinos.listdir(folder):iffile.endswith(.xlsx):dfpd.read_excel(os.path.join(folder,file))# 确保共同字段存在ifcommon_fieldnotindf.columns:print(f⚠{file}缺少字段{common_field}跳过)continueifmergedisNone:mergeddfelse:mergedmerged.merge(df,oncommon_field,howouter)ifmergedisnotNone:merged.to_excel(output_path,indexFalse)print(f合并完成按{common_field}关联)TEMU店群矩阵自动化运营核价报活动同步的可靠性保障同步不是跑一次就完事的操作它需要保障机制。1. 数据校验同步完成后的数据量是否对得上src_countlen(source_df)dest_countpd.read_excel(dest_path).shape[0]ifsrc_count!dest_count:print(f⚠ 数据量不一致源{src_count}→ 目标{dest_count})else:print(f✓ 数据量一致{src_count}条)2. 不怕重复跑幂等性同一个同步脚本跑两次不应该产生重复数据。使用if_existsreplace全量覆盖天然是幂等的。增量同步需要在写入前检查是否已存在。3. 写操作失败回滚如果写Excel时中途出错应该保留旧版本不要覆盖importtempfiledefsafe_write_excel(df,path):安全写入先写临时文件成功后再替换tmp_pathpath.tmpdf.to_excel(tmp_path,indexFalse)os.replace(tmp_path,path)# 原子替换总结跨平台数据同步底层就是三个动作读 → 转 → 写。Excel、SQLite、飞书、CSV之间的六对组合掌握好读和写两端的方法中间的转用pandas搞定。同步不等于复制——要有数据校验、增量策略、失败保护。让数据自己流动起来而不是你手动搬运。内容标签#影刀RPA #数据同步 #Excel #飞书 #SQLite #pandas作者林焱系列影刀RPA进阶教程系列——让数据在系统间自由流动
影刀RPA进阶教程跨平台数据同步方案Excel飞书数据库之间的一键互通你的数据散落在三个地方电商后台导出的数据在Excel里团队协作的数据在飞书多维表格里历史归档的数据在SQLite数据库里每次做分析你要手动从三个地方导出、拼接、去重。如果这三个地方的数据能自动互相同步——你的工作就少了80%。这篇文章讲的就是数据跨平台同步这件事。同步的本质是什么跨平台数据同步本质上是三个动作的循环读取源A → 转换格式 → 写入目标B所有同步方案都是这个结构的变体。区别只在于源是什么Excel、飞书、数据库、API目标是什么同上转换逻辑有多复杂直接复制、字段映射、计算衍生字段同步一Excel ↔ SQLite这是最常见的同步场景——采集数据到Excel需要入库持久化。Excel → SQLite拼多多店群自动化报活动上架importpandasaspdimportsqlite3defexcel_to_sqlite(excel_path,db_path,table_name,modereplace):将Excel数据同步到SQLitedfpd.read_excel(excel_path)connsqlite3.connect(db_path)ifmodereplace:df.to_sql(table_name,conn,if_existsreplace,indexFalse)elifmodeappend:df.to_sql(table_name,conn,if_existsappend,indexFalse)elifmodeupsert:# 先建临时表再用INSERT OR REPLACEdf.to_sql(f{table_name}_tmp,conn,if_existsreplace,indexFalse)conn.execute(fDELETE FROM{table_name}WHERE 日期 IN (SELECT 日期 FROM{table_name}_tmp))conn.execute(fINSERT INTO{table_name}SELECT * FROM{table_name}_tmp)conn.execute(fDROP TABLE{table_name}_tmp)conn.commit()conn.close()print(f同步完成{len(df)}条 →{table_name})SQLite → Exceldefsqlite_to_excel(db_path,table_name,excel_path,queryNone):将SQLite数据导出到Excelconnsqlite3.connect(db_path)ifquery:dfpd.read_sql_query(query,conn)else:dfpd.read_sql_query(fSELECT * FROM{table_name},conn)df.to_excel(excel_path,indexFalse)conn.close()print(f导出完成{len(df)}条 →{excel_path})增量同步只同步新增的数据全量同步简单但每次都重写整个表。数据多了以后很慢。增量同步只处理新增和变更的数据defincremental_sync(excel_path,db_path,table_name,key_columnid):增量同步只同步Excel中新增和变更的记录df_newpd.read_excel(excel_path)connsqlite3.connect(db_path)# 获取数据库中已有的ID集合existing_idsset(pd.read_sql_query(fSELECT{key_column}FROM{table_name},conn)[key_column].values)# 分离新增和变更new_idsset(df_new[key_column].values)to_insertdf_new[~df_new[key_column].isin(existing_ids)]to_updatedf_new[df_new[key_column].isin(existing_ids)]# 插入新增to_insert.to_sql(table_name,conn,if_existsappend,indexFalse)# 更新已有用temp table updateiflen(to_update)0:to_update.to_sql(_tmp_update,conn,if_existsreplace,indexFalse)# 构建UPDATE语句...这里简化处理实际按需写conn.commit()conn.close()print(f增量同步新增{len(to_insert)}更新{len(to_update)})同步二飞书多维表格 ↔ Excel飞书多维表格 → Excel读取飞书数据到本地importrequestsimportpandasaspddeffeishu_bitable_to_excel(app_token,table_id,token,excel_path):读取飞书多维表格并导出为Excelheaders{Authorization:fBearer{token}}all_records[]page_tokenNonewhileTrue:urlfhttps://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/recordsparams{page_size:500}ifpage_token:params[page_token]page_token resprequests.get(url,headersheaders,paramsparams)dataresp.json()forrecordindata.get(data,{}).get(items,[]):all_records.append(record[fields])ifnotdata.get(data,{}).get(has_more):breakpage_tokendata[data][page_token]dfpd.DataFrame(all_records)df.to_excel(excel_path,indexFalse)print(f飞书 → Excel{len(df)}条)Excel → 飞书多维表格参考上一篇飞书文档的文章用batch_create接口写入。定时双向同步策略每天 08:00飞书 → 本地SQLite拉取最新线上数据 每天 20:00本地SQLite → 飞书推送今日采集结果避免同一时间双向同步——可能导致数据冲突。同步三Excel ↔ CSV简单但高频的场景。Excel → CSVdfpd.read_excel(data.xlsx)df.to_csv(data.csv,indexFalse,encodingutf-8-sig)CSV → Exceldfpd.read_csv(data.csv)df.to_excel(data.xlsx,indexFalse)批量转换importglobdefbatch_csv_to_excel(folder,output_folderNone):把一个文件夹里的所有CSV转成xlsxifoutput_folderisNone:output_folderfolder csv_filesglob.glob(os.path.join(folder,*.csv))forcsv_fileincsv_files:dfpd.read_csv(csv_file)basenameos.path.splitext(os.path.basename(csv_file))[0]excel_pathos.path.join(output_folder,f{basename}.xlsx)df.to_excel(excel_path,indexFalse)print(f✓{basename})print(f批量转换完成{len(csv_files)}个文件)同步四多个Excel文件合并同步你的数据可能来自不同部门每个部门一个Excel。相同结构合并defmerge_excel_files(folder,output_path):合并同一文件夹下所有xlsx文件结构相同all_dfs[]forfileinos.listdir(folder):iffile.endswith(.xlsx)andnotfile.startswith(~):file_pathos.path.join(folder,file)dfpd.read_excel(file_path)df[来源文件]file# 加个标记列all_dfs.append(df)mergedpd.concat(all_dfs,ignore_indexTrue)merged.to_excel(output_path,indexFalse)print(f合并完成{len(all_dfs)}个文件 →{len(merged)}行)不同结构但有共同字段defmerge_by_common_field(folder,common_field,output_path):按共同字段合并不同结构的ExcelmergedNoneforfileinos.listdir(folder):iffile.endswith(.xlsx):dfpd.read_excel(os.path.join(folder,file))# 确保共同字段存在ifcommon_fieldnotindf.columns:print(f⚠{file}缺少字段{common_field}跳过)continueifmergedisNone:mergeddfelse:mergedmerged.merge(df,oncommon_field,howouter)ifmergedisnotNone:merged.to_excel(output_path,indexFalse)print(f合并完成按{common_field}关联)TEMU店群矩阵自动化运营核价报活动同步的可靠性保障同步不是跑一次就完事的操作它需要保障机制。1. 数据校验同步完成后的数据量是否对得上src_countlen(source_df)dest_countpd.read_excel(dest_path).shape[0]ifsrc_count!dest_count:print(f⚠ 数据量不一致源{src_count}→ 目标{dest_count})else:print(f✓ 数据量一致{src_count}条)2. 不怕重复跑幂等性同一个同步脚本跑两次不应该产生重复数据。使用if_existsreplace全量覆盖天然是幂等的。增量同步需要在写入前检查是否已存在。3. 写操作失败回滚如果写Excel时中途出错应该保留旧版本不要覆盖importtempfiledefsafe_write_excel(df,path):安全写入先写临时文件成功后再替换tmp_pathpath.tmpdf.to_excel(tmp_path,indexFalse)os.replace(tmp_path,path)# 原子替换总结跨平台数据同步底层就是三个动作读 → 转 → 写。Excel、SQLite、飞书、CSV之间的六对组合掌握好读和写两端的方法中间的转用pandas搞定。同步不等于复制——要有数据校验、增量策略、失败保护。让数据自己流动起来而不是你手动搬运。内容标签#影刀RPA #数据同步 #Excel #飞书 #SQLite #pandas作者林焱系列影刀RPA进阶教程系列——让数据在系统间自由流动
影刀RPA进阶教程_跨平台数据同步方案Excel飞书数据库之间的一键互通
发布时间:2026/6/17 20:47:16
影刀RPA进阶教程跨平台数据同步方案Excel飞书数据库之间的一键互通你的数据散落在三个地方电商后台导出的数据在Excel里团队协作的数据在飞书多维表格里历史归档的数据在SQLite数据库里每次做分析你要手动从三个地方导出、拼接、去重。如果这三个地方的数据能自动互相同步——你的工作就少了80%。这篇文章讲的就是数据跨平台同步这件事。同步的本质是什么跨平台数据同步本质上是三个动作的循环读取源A → 转换格式 → 写入目标B所有同步方案都是这个结构的变体。区别只在于源是什么Excel、飞书、数据库、API目标是什么同上转换逻辑有多复杂直接复制、字段映射、计算衍生字段同步一Excel ↔ SQLite这是最常见的同步场景——采集数据到Excel需要入库持久化。Excel → SQLite拼多多店群自动化报活动上架importpandasaspdimportsqlite3defexcel_to_sqlite(excel_path,db_path,table_name,modereplace):将Excel数据同步到SQLitedfpd.read_excel(excel_path)connsqlite3.connect(db_path)ifmodereplace:df.to_sql(table_name,conn,if_existsreplace,indexFalse)elifmodeappend:df.to_sql(table_name,conn,if_existsappend,indexFalse)elifmodeupsert:# 先建临时表再用INSERT OR REPLACEdf.to_sql(f{table_name}_tmp,conn,if_existsreplace,indexFalse)conn.execute(fDELETE FROM{table_name}WHERE 日期 IN (SELECT 日期 FROM{table_name}_tmp))conn.execute(fINSERT INTO{table_name}SELECT * FROM{table_name}_tmp)conn.execute(fDROP TABLE{table_name}_tmp)conn.commit()conn.close()print(f同步完成{len(df)}条 →{table_name})SQLite → Exceldefsqlite_to_excel(db_path,table_name,excel_path,queryNone):将SQLite数据导出到Excelconnsqlite3.connect(db_path)ifquery:dfpd.read_sql_query(query,conn)else:dfpd.read_sql_query(fSELECT * FROM{table_name},conn)df.to_excel(excel_path,indexFalse)conn.close()print(f导出完成{len(df)}条 →{excel_path})增量同步只同步新增的数据全量同步简单但每次都重写整个表。数据多了以后很慢。增量同步只处理新增和变更的数据defincremental_sync(excel_path,db_path,table_name,key_columnid):增量同步只同步Excel中新增和变更的记录df_newpd.read_excel(excel_path)connsqlite3.connect(db_path)# 获取数据库中已有的ID集合existing_idsset(pd.read_sql_query(fSELECT{key_column}FROM{table_name},conn)[key_column].values)# 分离新增和变更new_idsset(df_new[key_column].values)to_insertdf_new[~df_new[key_column].isin(existing_ids)]to_updatedf_new[df_new[key_column].isin(existing_ids)]# 插入新增to_insert.to_sql(table_name,conn,if_existsappend,indexFalse)# 更新已有用temp table updateiflen(to_update)0:to_update.to_sql(_tmp_update,conn,if_existsreplace,indexFalse)# 构建UPDATE语句...这里简化处理实际按需写conn.commit()conn.close()print(f增量同步新增{len(to_insert)}更新{len(to_update)})同步二飞书多维表格 ↔ Excel飞书多维表格 → Excel读取飞书数据到本地importrequestsimportpandasaspddeffeishu_bitable_to_excel(app_token,table_id,token,excel_path):读取飞书多维表格并导出为Excelheaders{Authorization:fBearer{token}}all_records[]page_tokenNonewhileTrue:urlfhttps://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/recordsparams{page_size:500}ifpage_token:params[page_token]page_token resprequests.get(url,headersheaders,paramsparams)dataresp.json()forrecordindata.get(data,{}).get(items,[]):all_records.append(record[fields])ifnotdata.get(data,{}).get(has_more):breakpage_tokendata[data][page_token]dfpd.DataFrame(all_records)df.to_excel(excel_path,indexFalse)print(f飞书 → Excel{len(df)}条)Excel → 飞书多维表格参考上一篇飞书文档的文章用batch_create接口写入。定时双向同步策略每天 08:00飞书 → 本地SQLite拉取最新线上数据 每天 20:00本地SQLite → 飞书推送今日采集结果避免同一时间双向同步——可能导致数据冲突。同步三Excel ↔ CSV简单但高频的场景。Excel → CSVdfpd.read_excel(data.xlsx)df.to_csv(data.csv,indexFalse,encodingutf-8-sig)CSV → Exceldfpd.read_csv(data.csv)df.to_excel(data.xlsx,indexFalse)批量转换importglobdefbatch_csv_to_excel(folder,output_folderNone):把一个文件夹里的所有CSV转成xlsxifoutput_folderisNone:output_folderfolder csv_filesglob.glob(os.path.join(folder,*.csv))forcsv_fileincsv_files:dfpd.read_csv(csv_file)basenameos.path.splitext(os.path.basename(csv_file))[0]excel_pathos.path.join(output_folder,f{basename}.xlsx)df.to_excel(excel_path,indexFalse)print(f✓{basename})print(f批量转换完成{len(csv_files)}个文件)同步四多个Excel文件合并同步你的数据可能来自不同部门每个部门一个Excel。相同结构合并defmerge_excel_files(folder,output_path):合并同一文件夹下所有xlsx文件结构相同all_dfs[]forfileinos.listdir(folder):iffile.endswith(.xlsx)andnotfile.startswith(~):file_pathos.path.join(folder,file)dfpd.read_excel(file_path)df[来源文件]file# 加个标记列all_dfs.append(df)mergedpd.concat(all_dfs,ignore_indexTrue)merged.to_excel(output_path,indexFalse)print(f合并完成{len(all_dfs)}个文件 →{len(merged)}行)不同结构但有共同字段defmerge_by_common_field(folder,common_field,output_path):按共同字段合并不同结构的ExcelmergedNoneforfileinos.listdir(folder):iffile.endswith(.xlsx):dfpd.read_excel(os.path.join(folder,file))# 确保共同字段存在ifcommon_fieldnotindf.columns:print(f⚠{file}缺少字段{common_field}跳过)continueifmergedisNone:mergeddfelse:mergedmerged.merge(df,oncommon_field,howouter)ifmergedisnotNone:merged.to_excel(output_path,indexFalse)print(f合并完成按{common_field}关联)TEMU店群矩阵自动化运营核价报活动同步的可靠性保障同步不是跑一次就完事的操作它需要保障机制。1. 数据校验同步完成后的数据量是否对得上src_countlen(source_df)dest_countpd.read_excel(dest_path).shape[0]ifsrc_count!dest_count:print(f⚠ 数据量不一致源{src_count}→ 目标{dest_count})else:print(f✓ 数据量一致{src_count}条)2. 不怕重复跑幂等性同一个同步脚本跑两次不应该产生重复数据。使用if_existsreplace全量覆盖天然是幂等的。增量同步需要在写入前检查是否已存在。3. 写操作失败回滚如果写Excel时中途出错应该保留旧版本不要覆盖importtempfiledefsafe_write_excel(df,path):安全写入先写临时文件成功后再替换tmp_pathpath.tmpdf.to_excel(tmp_path,indexFalse)os.replace(tmp_path,path)# 原子替换总结跨平台数据同步底层就是三个动作读 → 转 → 写。Excel、SQLite、飞书、CSV之间的六对组合掌握好读和写两端的方法中间的转用pandas搞定。同步不等于复制——要有数据校验、增量策略、失败保护。让数据自己流动起来而不是你手动搬运。内容标签#影刀RPA #数据同步 #Excel #飞书 #SQLite #pandas作者林焱系列影刀RPA进阶教程系列——让数据在系统间自由流动







)









