 影刀RPA实操指南微信公众号文章批量采集从搜狗微信到内容归档的完整链路你想研究竞品的公众号内容策略。或者你想批量采集某个行业的公众号文章做分析。或者你的老板让你把公司公众号的所有历史文章导出备份。这些需求的共同点是微信公众号的内容不是传统网页需要特殊的方法来采集。这篇文章给你一套完整的微信公众号文章采集方案。微信公众号内容的特殊性和淘宝、京东这些标准网页不同微信公众号有以下特点内容不在微信客户端外直接可见。你没法像打开淘宝商品页那样直接访问文章列表通过API加载不是标准的HTML翻页反爬严格频率太高容易被封文章URL有时效性过期的临时链接打不开采集方案需要针对这些特点设计。方案一搜狗微信搜索最推荐新手搜狗是微信官方授权的搜索引擎可以搜索微信公众号文章。获取文章列表这是一个纯网页操作影刀可以搞定1. 打开URLhttps://weixin.sogou.com/ 2. 点击微信标签 3. 输入搜索关键词 → 搜索 4. 获取文章列表 XPath: //ul[classnews-list]/li 循环 - 标题.//h3/a/text() - 摘要.//p[classtxt-info]/text() - 来源公众号.//a[classaccount]/text() - 发布时间.//span[classs2]/text() - 文章链接.//h3/a/href 5. 翻页 → 重复步骤4处理反爬搜狗有频率限制。建议翻页间隔至少3秒每5页换一个User-Agent一天内同一关键词不要超过50页店群矩阵自动化突破运营极限打开文章详情搜狗返回的文章链接不是直接的公众号文章URL而是一个跳转链接。点进去后才是真正的文章页面。影刀操作6. 循环文章链接 6.1 打开新标签页链接URL 6.2 等待页面加载判断文章标题元素出现 6.3 提取文章内容 - 标题//h2[idactivity-name] - 发布时间//em[idpost-date] - 公众号名称//a[idjs_name] - 正文//div[idjs_content] 6.4 保存到本地 6.5 关闭标签页注意每篇打开间隔至少5秒搜狗对短时间内打开大量文章详情也很敏感。方案二公众号主页采集需微信客户端如果你需要采集特定公众号的所有历史文章可以通过PC版微信客户端操作。步骤1. 影刀打开PC微信 2. 搜索目标公众号 3. 进入公众号聊天窗口 4. 点击公众号头像 → 进入公众号主页 5. 点击查看全部消息 6. 滚动加载文章列表无限滚动 7.  8. 逐条提取文章标题和链接 9. 点击文章链接 → 提取正文 10. 循环这个方案依赖PC微信客户端只能在工作时间窗口内操作而且微信版本更新可能影响影刀的元素定位。更稳定的做法用模拟操作打开公众号主页的历史消息页面通过鼠标滚轮加载更多文章。指令鼠标滚轮 目标文章列表区域 滚动次数每次滚动到底部 → 等3秒加载 循环直到出现没有更多了或滚动次数超过预期方案三公众号文章链接采集需要已有链接如果你已经有一个公众号的文章URL列表比如从其他渠道获取直接循环采集即可。文章URL的特征微信公众号文章URL长这样https://mp.weixin.qq.com/s/xxxxxs/后面是一串随机字符每篇文章都不一样。批量采集1. 准备文章URL列表Excel/CSV/文本文件 2. 循环URL列表 2.1 打开URL 2.2 等待文章加载 2.3 提取标题/发布时间/作者/正文/阅读数如果有 2.4 保存到本地/Markdown/数据库 2.5 随机等待3-8秒 2.6 关闭标签页 3. 汇总所有文章索引数据存储Markdown格式保存公众号文章里面有很多格式加粗、图片、引用纯文本保存会丢失这些信息。建议存为Markdown格式defsave_as_markdown(title,author,pub_date,content,output_dir):将公众号文章保存为Markdown文件importrefromdatetimeimportdatetime# 清理文件名中的非法字符safe_titlere.sub(r[\\/:*?|],_,title)filenamef{pub_date}_{safe_title[:50]}.mdfilepathos.path.join(output_dir,filename)md_contentf--- title:{title}author:{author}date:{pub_date}source: 微信公众号 --- #{title} 作者{author}| 发布时间{pub_date}{content}withopen(filepath,w,encodingutf-8)asf:f.write(md_content)returnfilepath图片的处理微信公众号文章的图片URL有时效性可能过几天就失效了。如果需要长期保存把图片下载到本地importrequestsimportredefdownload_images_from_html(html,output_dir):下载HTML中的所有图片到本地img_urlsre.findall(rdata-src(https?://[^]),html)downloaded[]fori,urlinenumerate(img_urls):try:resprequests.get(url,timeout10)exturl.split(.)[-1].split(?)[0]orjpgfilenamefimg_{i1:03d}.{ext}filepathos.path.join(output_dir,filename)withopen(filepath,wb)asf:f.write(resp.content)downloaded.append(filepath)except:passreturndownloaded反爬策略汇总风险应对IP被封减小频率、使用代理搜狗验证码人工介入频率太高触发文章临时链接过期采集后立即归档微信客户端弹窗机器人检测弹窗 → 停止操作图片防盗链下载图片时带Referer最重要的原则控制频率。每篇文章之间至少间隔3-5秒每次采集总量控制在200篇以内。文章分析采集之后做什么采集只是第一步分析才是目的。基础指标提取temu店群自动化报活动案例# 从文章正文提取词频importjiebafromcollectionsimportCounterdefanalyze_articles(articles):words[]forarticleinarticles:segjieba.cut(article[content])words.extend([wforwinsegiflen(w)2])counterCounter(words)returncounter.most_common(100)# Top 100高频词时间分布分析importpandasaspd dfpd.DataFrame(articles)df[pub_date]pd.to_datetime(df[pub_date])df[weekday]df[pub_date].dt.weekday df[hour]df[pub_date].dt.hour 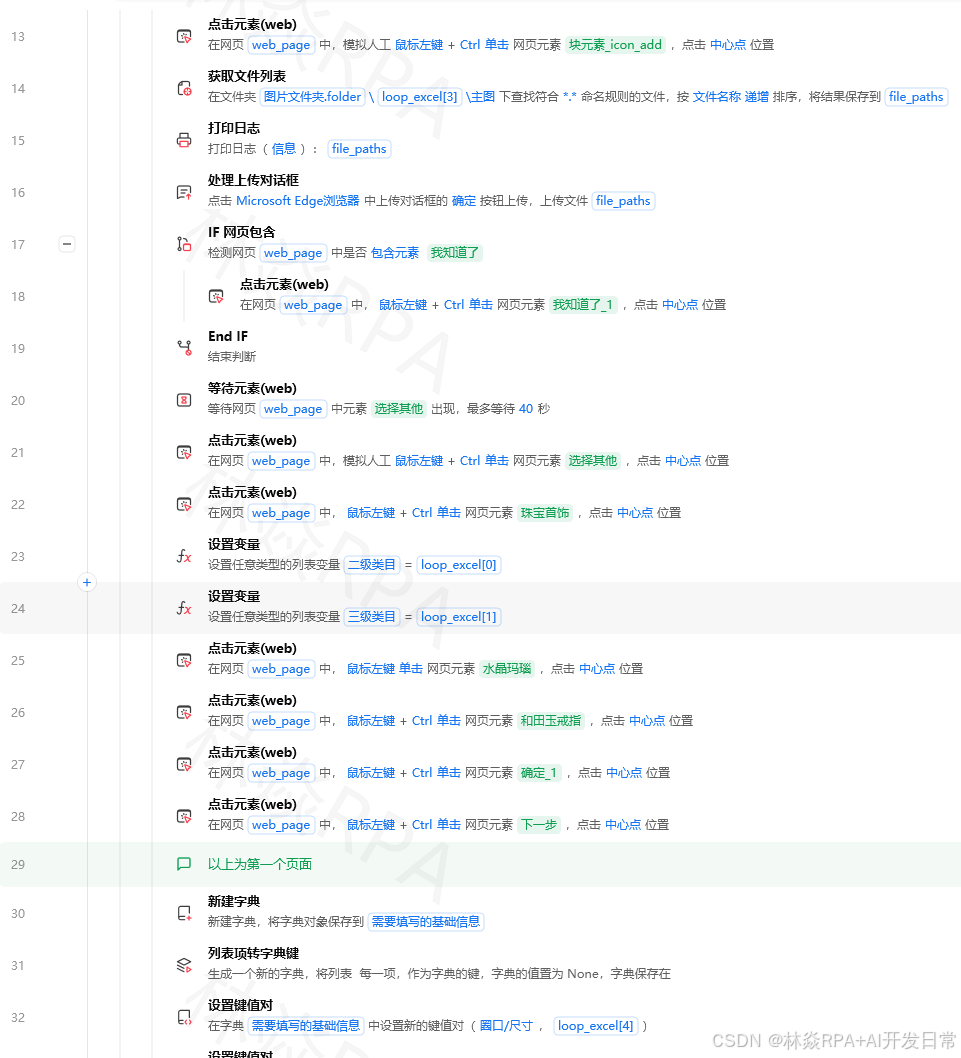# 分析发文时间分布publish_patterndf.groupby(weekday).size()print(publish_pattern)避坑清单坑1搜狗文章链接打不开搜狗返回的链接是https://weixin.sogou.com/link?url...这种跳转链接需要先让浏览器跳转一次才能到真正的文章页。影刀直接打开链接浏览器会自动完成跳转不用额外处理。坑2文章正文被折叠有些长文章微信会自动折叠需要点击阅读全文才能展开。如果 元素存在(//a[contains(text(),阅读全文)]) 点击元素(//a[contains(text(),阅读全文)]) 等待1秒坑3阅读数获取文章详情页的阅读数是通过JS动态加载的不一定能直接获取。实测//span[idreadNum]有时候有值有时候没有。不稳定就不要强求。总结微信公众号文章采集的三个方案搜狗搜索最通用、微信客户端操作适合特定公众号、已有链接批量采集最稳定。核心原则控制频率、及时归档、做好反爬应对。采集后的文章建议存为Markdown格式保留格式信息图片下载到本地避免链接过期。微信公众号的内容采集比电商网站复杂不少但掌握了套路之后就是体力活了。内容标签#影刀RPA #微信公众号 #内容采集 #搜狗 #数据分析作者林焱系列影刀RPA实操指南系列——探索非标准平台的数据采集方案
影刀RPA实操指南微信公众号文章批量采集从搜狗微信到内容归档的完整链路你想研究竞品的公众号内容策略。或者你想批量采集某个行业的公众号文章做分析。或者你的老板让你把公司公众号的所有历史文章导出备份。这些需求的共同点是微信公众号的内容不是传统网页需要特殊的方法来采集。这篇文章给你一套完整的微信公众号文章采集方案。微信公众号内容的特殊性和淘宝、京东这些标准网页不同微信公众号有以下特点内容不在微信客户端外直接可见。你没法像打开淘宝商品页那样直接访问文章列表通过API加载不是标准的HTML翻页反爬严格频率太高容易被封文章URL有时效性过期的临时链接打不开采集方案需要针对这些特点设计。方案一搜狗微信搜索最推荐新手搜狗是微信官方授权的搜索引擎可以搜索微信公众号文章。获取文章列表这是一个纯网页操作影刀可以搞定1. 打开URLhttps://weixin.sogou.com/ 2. 点击微信标签 3. 输入搜索关键词 → 搜索 4. 获取文章列表 XPath: //ul[classnews-list]/li 循环 - 标题.//h3/a/text() - 摘要.//p[classtxt-info]/text() - 来源公众号.//a[classaccount]/text() - 发布时间.//span[classs2]/text() - 文章链接.//h3/a/href 5. 翻页 → 重复步骤4处理反爬搜狗有频率限制。建议翻页间隔至少3秒每5页换一个User-Agent一天内同一关键词不要超过50页店群矩阵自动化突破运营极限打开文章详情搜狗返回的文章链接不是直接的公众号文章URL而是一个跳转链接。点进去后才是真正的文章页面。影刀操作6. 循环文章链接 6.1 打开新标签页链接URL 6.2 等待页面加载判断文章标题元素出现 6.3 提取文章内容 - 标题//h2[idactivity-name] - 发布时间//em[idpost-date] - 公众号名称//a[idjs_name] - 正文//div[idjs_content] 6.4 保存到本地 6.5 关闭标签页注意每篇打开间隔至少5秒搜狗对短时间内打开大量文章详情也很敏感。方案二公众号主页采集需微信客户端如果你需要采集特定公众号的所有历史文章可以通过PC版微信客户端操作。步骤1. 影刀打开PC微信 2. 搜索目标公众号 3. 进入公众号聊天窗口 4. 点击公众号头像 → 进入公众号主页 5. 点击查看全部消息 6. 滚动加载文章列表无限滚动 7.  8. 逐条提取文章标题和链接 9. 点击文章链接 → 提取正文 10. 循环这个方案依赖PC微信客户端只能在工作时间窗口内操作而且微信版本更新可能影响影刀的元素定位。更稳定的做法用模拟操作打开公众号主页的历史消息页面通过鼠标滚轮加载更多文章。指令鼠标滚轮 目标文章列表区域 滚动次数每次滚动到底部 → 等3秒加载 循环直到出现没有更多了或滚动次数超过预期方案三公众号文章链接采集需要已有链接如果你已经有一个公众号的文章URL列表比如从其他渠道获取直接循环采集即可。文章URL的特征微信公众号文章URL长这样https://mp.weixin.qq.com/s/xxxxxs/后面是一串随机字符每篇文章都不一样。批量采集1. 准备文章URL列表Excel/CSV/文本文件 2. 循环URL列表 2.1 打开URL 2.2 等待文章加载 2.3 提取标题/发布时间/作者/正文/阅读数如果有 2.4 保存到本地/Markdown/数据库 2.5 随机等待3-8秒 2.6 关闭标签页 3. 汇总所有文章索引数据存储Markdown格式保存公众号文章里面有很多格式加粗、图片、引用纯文本保存会丢失这些信息。建议存为Markdown格式defsave_as_markdown(title,author,pub_date,content,output_dir):将公众号文章保存为Markdown文件importrefromdatetimeimportdatetime# 清理文件名中的非法字符safe_titlere.sub(r[\\/:*?|],_,title)filenamef{pub_date}_{safe_title[:50]}.mdfilepathos.path.join(output_dir,filename)md_contentf--- title:{title}author:{author}date:{pub_date}source: 微信公众号 --- #{title} 作者{author}| 发布时间{pub_date}{content}withopen(filepath,w,encodingutf-8)asf:f.write(md_content)returnfilepath图片的处理微信公众号文章的图片URL有时效性可能过几天就失效了。如果需要长期保存把图片下载到本地importrequestsimportredefdownload_images_from_html(html,output_dir):下载HTML中的所有图片到本地img_urlsre.findall(rdata-src(https?://[^]),html)downloaded[]fori,urlinenumerate(img_urls):try:resprequests.get(url,timeout10)exturl.split(.)[-1].split(?)[0]orjpgfilenamefimg_{i1:03d}.{ext}filepathos.path.join(output_dir,filename)withopen(filepath,wb)asf:f.write(resp.content)downloaded.append(filepath)except:passreturndownloaded反爬策略汇总风险应对IP被封减小频率、使用代理搜狗验证码人工介入频率太高触发文章临时链接过期采集后立即归档微信客户端弹窗机器人检测弹窗 → 停止操作图片防盗链下载图片时带Referer最重要的原则控制频率。每篇文章之间至少间隔3-5秒每次采集总量控制在200篇以内。文章分析采集之后做什么采集只是第一步分析才是目的。基础指标提取temu店群自动化报活动案例# 从文章正文提取词频importjiebafromcollectionsimportCounterdefanalyze_articles(articles):words[]forarticleinarticles:segjieba.cut(article[content])words.extend([wforwinsegiflen(w)2])counterCounter(words)returncounter.most_common(100)# Top 100高频词时间分布分析importpandasaspd dfpd.DataFrame(articles)df[pub_date]pd.to_datetime(df[pub_date])df[weekday]df[pub_date].dt.weekday df[hour]df[pub_date].dt.hour # 分析发文时间分布publish_patterndf.groupby(weekday).size()print(publish_pattern)避坑清单坑1搜狗文章链接打不开搜狗返回的链接是https://weixin.sogou.com/link?url...这种跳转链接需要先让浏览器跳转一次才能到真正的文章页。影刀直接打开链接浏览器会自动完成跳转不用额外处理。坑2文章正文被折叠有些长文章微信会自动折叠需要点击阅读全文才能展开。如果 元素存在(//a[contains(text(),阅读全文)]) 点击元素(//a[contains(text(),阅读全文)]) 等待1秒坑3阅读数获取文章详情页的阅读数是通过JS动态加载的不一定能直接获取。实测//span[idreadNum]有时候有值有时候没有。不稳定就不要强求。总结微信公众号文章采集的三个方案搜狗搜索最通用、微信客户端操作适合特定公众号、已有链接批量采集最稳定。核心原则控制频率、及时归档、做好反爬应对。采集后的文章建议存为Markdown格式保留格式信息图片下载到本地避免链接过期。微信公众号的内容采集比电商网站复杂不少但掌握了套路之后就是体力活了。内容标签#影刀RPA #微信公众号 #内容采集 #搜狗 #数据分析作者林焱系列影刀RPA实操指南系列——探索非标准平台的数据采集方案
影刀RPA实操指南_微信公众号文章批量采集从搜狗微信到内容归档的完整链路
发布时间:2026/6/13 21:29:12
影刀RPA实操指南微信公众号文章批量采集从搜狗微信到内容归档的完整链路你想研究竞品的公众号内容策略。或者你想批量采集某个行业的公众号文章做分析。或者你的老板让你把公司公众号的所有历史文章导出备份。这些需求的共同点是微信公众号的内容不是传统网页需要特殊的方法来采集。这篇文章给你一套完整的微信公众号文章采集方案。微信公众号内容的特殊性和淘宝、京东这些标准网页不同微信公众号有以下特点内容不在微信客户端外直接可见。你没法像打开淘宝商品页那样直接访问文章列表通过API加载不是标准的HTML翻页反爬严格频率太高容易被封文章URL有时效性过期的临时链接打不开采集方案需要针对这些特点设计。方案一搜狗微信搜索最推荐新手搜狗是微信官方授权的搜索引擎可以搜索微信公众号文章。获取文章列表这是一个纯网页操作影刀可以搞定1. 打开URLhttps://weixin.sogou.com/ 2. 点击微信标签 3. 输入搜索关键词 → 搜索 4. 获取文章列表 XPath: //ul[classnews-list]/li 循环 - 标题.//h3/a/text() - 摘要.//p[classtxt-info]/text() - 来源公众号.//a[classaccount]/text() - 发布时间.//span[classs2]/text() - 文章链接.//h3/a/href 5. 翻页 → 重复步骤4处理反爬搜狗有频率限制。建议翻页间隔至少3秒每5页换一个User-Agent一天内同一关键词不要超过50页店群矩阵自动化突破运营极限打开文章详情搜狗返回的文章链接不是直接的公众号文章URL而是一个跳转链接。点进去后才是真正的文章页面。影刀操作6. 循环文章链接 6.1 打开新标签页链接URL 6.2 等待页面加载判断文章标题元素出现 6.3 提取文章内容 - 标题//h2[idactivity-name] - 发布时间//em[idpost-date] - 公众号名称//a[idjs_name] - 正文//div[idjs_content] 6.4 保存到本地 6.5 关闭标签页注意每篇打开间隔至少5秒搜狗对短时间内打开大量文章详情也很敏感。方案二公众号主页采集需微信客户端如果你需要采集特定公众号的所有历史文章可以通过PC版微信客户端操作。步骤1. 影刀打开PC微信 2. 搜索目标公众号 3. 进入公众号聊天窗口 4. 点击公众号头像 → 进入公众号主页 5. 点击查看全部消息 6. 滚动加载文章列表无限滚动 7.  8. 逐条提取文章标题和链接 9. 点击文章链接 → 提取正文 10. 循环这个方案依赖PC微信客户端只能在工作时间窗口内操作而且微信版本更新可能影响影刀的元素定位。更稳定的做法用模拟操作打开公众号主页的历史消息页面通过鼠标滚轮加载更多文章。指令鼠标滚轮 目标文章列表区域 滚动次数每次滚动到底部 → 等3秒加载 循环直到出现没有更多了或滚动次数超过预期方案三公众号文章链接采集需要已有链接如果你已经有一个公众号的文章URL列表比如从其他渠道获取直接循环采集即可。文章URL的特征微信公众号文章URL长这样https://mp.weixin.qq.com/s/xxxxxs/后面是一串随机字符每篇文章都不一样。批量采集1. 准备文章URL列表Excel/CSV/文本文件 2. 循环URL列表 2.1 打开URL 2.2 等待文章加载 2.3 提取标题/发布时间/作者/正文/阅读数如果有 2.4 保存到本地/Markdown/数据库 2.5 随机等待3-8秒 2.6 关闭标签页 3. 汇总所有文章索引数据存储Markdown格式保存公众号文章里面有很多格式加粗、图片、引用纯文本保存会丢失这些信息。建议存为Markdown格式defsave_as_markdown(title,author,pub_date,content,output_dir):将公众号文章保存为Markdown文件importrefromdatetimeimportdatetime# 清理文件名中的非法字符safe_titlere.sub(r[\\/:*?|],_,title)filenamef{pub_date}_{safe_title[:50]}.mdfilepathos.path.join(output_dir,filename)md_contentf--- title:{title}author:{author}date:{pub_date}source: 微信公众号 --- #{title} 作者{author}| 发布时间{pub_date}{content}withopen(filepath,w,encodingutf-8)asf:f.write(md_content)returnfilepath图片的处理微信公众号文章的图片URL有时效性可能过几天就失效了。如果需要长期保存把图片下载到本地importrequestsimportredefdownload_images_from_html(html,output_dir):下载HTML中的所有图片到本地img_urlsre.findall(rdata-src(https?://[^]),html)downloaded[]fori,urlinenumerate(img_urls):try:resprequests.get(url,timeout10)exturl.split(.)[-1].split(?)[0]orjpgfilenamefimg_{i1:03d}.{ext}filepathos.path.join(output_dir,filename)withopen(filepath,wb)asf:f.write(resp.content)downloaded.append(filepath)except:passreturndownloaded反爬策略汇总风险应对IP被封减小频率、使用代理搜狗验证码人工介入频率太高触发文章临时链接过期采集后立即归档微信客户端弹窗机器人检测弹窗 → 停止操作图片防盗链下载图片时带Referer最重要的原则控制频率。每篇文章之间至少间隔3-5秒每次采集总量控制在200篇以内。文章分析采集之后做什么采集只是第一步分析才是目的。基础指标提取temu店群自动化报活动案例# 从文章正文提取词频importjiebafromcollectionsimportCounterdefanalyze_articles(articles):words[]forarticleinarticles:segjieba.cut(article[content])words.extend([wforwinsegiflen(w)2])counterCounter(words)returncounter.most_common(100)# Top 100高频词时间分布分析importpandasaspd dfpd.DataFrame(articles)df[pub_date]pd.to_datetime(df[pub_date])df[weekday]df[pub_date].dt.weekday df[hour]df[pub_date].dt.hour # 分析发文时间分布publish_patterndf.groupby(weekday).size()print(publish_pattern)避坑清单坑1搜狗文章链接打不开搜狗返回的链接是https://weixin.sogou.com/link?url...这种跳转链接需要先让浏览器跳转一次才能到真正的文章页。影刀直接打开链接浏览器会自动完成跳转不用额外处理。坑2文章正文被折叠有些长文章微信会自动折叠需要点击阅读全文才能展开。如果 元素存在(//a[contains(text(),阅读全文)]) 点击元素(//a[contains(text(),阅读全文)]) 等待1秒坑3阅读数获取文章详情页的阅读数是通过JS动态加载的不一定能直接获取。实测//span[idreadNum]有时候有值有时候没有。不稳定就不要强求。总结微信公众号文章采集的三个方案搜狗搜索最通用、微信客户端操作适合特定公众号、已有链接批量采集最稳定。核心原则控制频率、及时归档、做好反爬应对。采集后的文章建议存为Markdown格式保留格式信息图片下载到本地避免链接过期。微信公众号的内容采集比电商网站复杂不少但掌握了套路之后就是体力活了。内容标签#影刀RPA #微信公众号 #内容采集 #搜狗 #数据分析作者林焱系列影刀RPA实操指南系列——探索非标准平台的数据采集方案














