 面试官来讲讲 Transformer 架构的基本原理Encoder 和 Decoder 是什么♂️我Transformer 是 Google 提的一个新架构核心是 Attention效果比 RNN 好很多。Encoder 是编码器Decoder 是解码器。面试官……「编码器」「解码器」是中文翻译我问的是它们具体在做什么不是字面意思。再说Attention 凭什么比 RNN 好RNN 到底有什么致命缺陷♂️我哦哦应该是 RNN 太慢了Attention 能并行计算面试官方向对了一半。但你只说了「快」没说「准」。RNN 还有一个更致命的问题长距离信息会衰减第 1 个词的信息传到第 800 个词基本就没了。Attention 怎么解决这个问题的能讲清楚吗♂️我呃……Attention 让每个词都能看到所有其他词面试官勉强能说出来。那再问一个BERT 用的是 Encoder-onlyGPT 用的是 Decoder-only。为什么现在主流大模型GPT、Claude、Qwen全部选择了 Decoder-only这种架构选型背后的原因你能讲清楚吗♂️我呃……面试官典型的「知道有但讲不清」。Decoder-only 赢的根本原因是「预测下一个 token」这个训练目标极其统一所有 NLP 任务都能用它表达。这种「为什么 X 赢了 Y」的演进逻辑搞不清楚去面试就是被怼。回去补一下。这几个反问串起来其实就是一条主线Transformer 这道题想听的不是「Attention is all you need」这种口号而是 RNN 卡在哪两点、Attention 怎么把这两点都破了、三种架构变体打了一圈为什么是 Decoder-only 赢到现在。 简要回答我理解 Transformer 最核心的创新是 Self-Attention让每个 token 都能直接和序列里任意其他位置建立联系一次性并行计算彻底解决了 RNN 顺序计算慢、长距离信息衰减的两个老问题。理解 Encoder 和 Decoder 的区别时我用这个角度Encoder 是双向的每个词能同时看前后文适合做「理解」类任务Decoder 是单向的只能看前面的词天然适合「生成」任务。至于为什么现代大模型GPT、Claude、Qwen都选 Decoder-only核心原因是「预测下一个 token」这个训练目标极其统一、可以直接在海量无标注文本上做自监督学习规模越大涌现出的能力越强。 详细解析Transformer 之前RNN 的致命缺陷在 Transformer 出现之前处理序列数据的主流方法是 RNN循环神经网络及其变体LSTM、GRU。RNN 的问题有两个而且都是致命的。第一个是顺序计算无法并行。RNN 处理序列的方式是从左到右逐个处理每个词第 N 步必须等第 N-1 步计算完才能开始无法利用 GPU 的并行计算能力。这导致训练大型 RNN 极慢。第二个是长距离梯度消失。当序列很长时比如 1000 个词RNN 理论上能记住早期的信息但实践中梯度在反向传播时会指数级衰减网络很难学习到「第 1 个词和第 800 个词之间的关系」。LSTM 通过门控机制有所缓解但根本问题没解决。2017 年 Google 在论文《Attention is All You Need》里提出了 Transformer用一个全新的架构一举解决了这两个问题。Self-Attention 的核心直觉Self-Attention自注意力的核心思路是让序列中的每个 token 都能直接关注序列中任意其他位置的 token计算出「我和其他位置的相关程度」然后根据相关程度加权聚合其他位置的信息。这里有三个关键向量QQuery查询代表「我想找什么」KKey键代表「我有什么标签」VValue值代表「我的实际内容」。可以用图书馆检索来类比你有一个搜索关键词Q图书馆里每本书都有标签K和内容V。注意力机制就是用你的关键词Q去匹配每本书的标签K计算出相似度分数然后按照分数的权重把书的内容V加权求和得到你的搜索结果。Q/K/V 是怎么从输入变换得到的很多人讲 Self-Attention 容易卡在「Q/K/V 是从哪儿冒出来的」这一步。其实 Q/K/V 不是模型「凭空生成」的而是把输入 embedding 通过三个独立的线性投影矩阵W_Q、W_K、W_V 算出来的# 假设输入 X 是 (序列长度 N, embedding 维度 d_model)# W_Q, W_K, W_V 都是可训练参数矩阵形状 (d_model, d_k)Q X W_Q # 形状 (N, d_k)每个 token 都有自己的 Query 向量K X W_K # 形状 (N, d_k)每个 token 都有自己的 Key 向量V X W_V # 形状 (N, d_v)每个 token 都有自己的 Value 向量 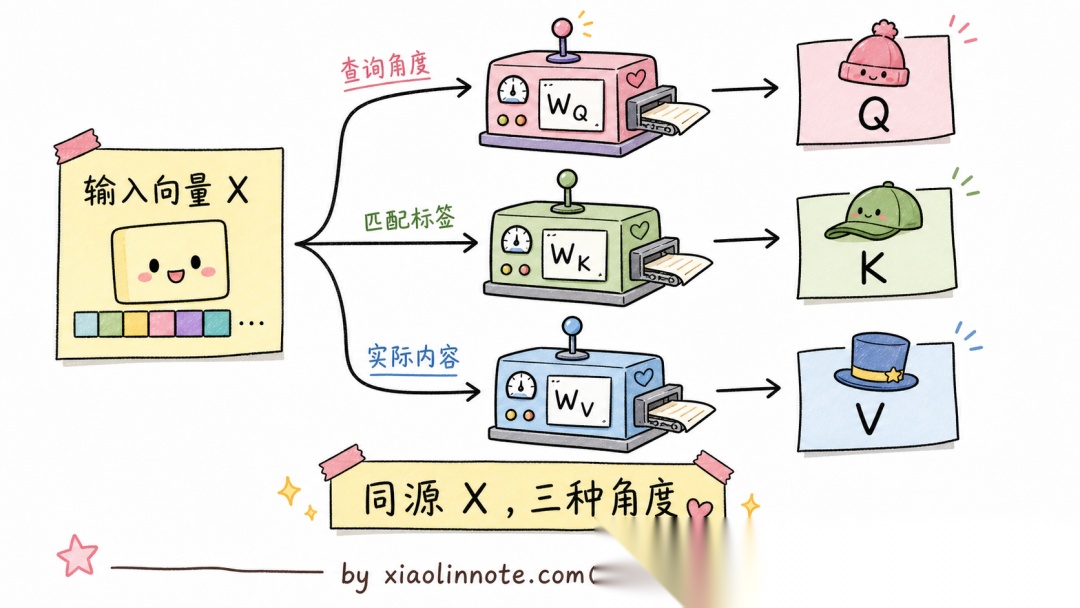 这一步就是面试里常被追问的「**Q/K/V 是怎么得到的**」。理解的时候有几个关键点要抓住。 最关键的一点是 Q/K/V 都是**从同一个输入 X 算出来**的。也就是说输入既要扮演「提问者」Q也要扮演「被查者」K V这就是「**自**注意力」里那个「自」字的含义区别于 Encoder-Decoder 架构里 Cross-Attention 那种「Q 来自一边、K/V 来自另一边」的形式。 然后 W\_Q、W\_K、W\_V 是三个**独立学习**的矩阵。这是个容易被忽略的细节但很重要。如果让 Q/K/V 都直接等于 X 不做变换模型就没法学到「该从什么角度提问」「该用什么标签匹配」「该返回什么内容」这种细致的差异。三个独立投影让模型有 3 倍的自由度去学习这种角度上的差异模型容量大幅提升。 还有一个工程细节是投影维度 d\_k 通常等于 d\_model / HH 是头数。比如 d\_model512、H8 时d\_k64。这样做的目的是让多头总参数量和单头版本基本一致不增加额外的计算开销。 到这里Q/K/V 三个向量就准备好了可以代入注意力公式 plaintext Attention(Q, K, V) softmax(Q · K^T / √d_k) · V为什么要除以 √d_k缩放点积的数学直觉公式里的/√d_k这一步常被叫做Scaled Dot-Product Attention缩放点积注意力。这个 √d_k 不是随便加的背后有具体的数学动机。直觉上的问题是这样的当 d_k 很大时比如 d_k128Q 和 K 都是 128 维的向量它们的点积是 128 个数相加。假设 Q 和 K 的每一维都是均值 0、方差 1 的随机数那么点积 Q·K 的方差就是 d_k128标准差是 √128 ≈ 11.3。这意味着点积的数值会散布在 -30 到 30 这种很大的范围。然后这些数过 softmax 会发生什么softmax 对极端大的输入特别敏感最大的那个数对应的概率会接近 1其他数的概率会接近 0输出几乎变成 one-hot 分布。one-hot 分布的问题是梯度消失。softmax 的梯度公式里有p · (1-p)项p 接近 0 或 1 时梯度都接近 0。整个 Attention 层的反向传播信号被压扁模型训不起来。除以 √d_k 之后点积的方差被压回 1softmax 输出分布合理梯度能正常传播。那能不能用其他方案替代 √d_k理论上可以但 √d_k 是数学上最自然的选择。业界确实尝试过几种替代方案。一种是用 Layer Norm 来归一化比如某些 Attention 变体Pre-LN Transformer会在 Attention 之前先把输入归一化到固定范围这样后续的点积值天然就不会爆炸。但严格来说这是「在 Attention 之前做归一化」不是真的替换 √d_k 本身。另一种是让模型自己学一个 scaling 参数用一个可学习的标量代替 √d_k。实测效果和 √d_k 差不多但增加了可学习参数反而不如固定常数简洁。还有一种早期方案是直接限制 d_k 很小比如 d_k8让点积自然不会爆炸但这等于直接限制了模型的容量不划算。实践中所有主流 Transformer 实现GPT、LLaMA、Qwen 等都用 √d_k没有改。这是一个被 8 年实践验证的「简单且数学上合理」的选择。回到主线除以 √d_k 之后softmax 的输出就是稳定的注意力权重再用这些权重对 V 做加权求和就得到了 Self-Attention 的最终输出。整个过程对序列中所有位置的计算是可以并行的完美解决了 RNN 的并行问题而且每对位置之间都有直接连接通过注意力分数不存在长距离信息衰减的问题。Multi-Head Attention多角度观察单组 Q/K/V 只能学习到一种「关联关系」但语言中的关联是多维度的「我」和「吃」是主谓关系「苹果」和「吃」是宾动关系「苹果」和前文的「苹果树」是指代关系这些不同类型的关联需要不同的「注意力头」来捕捉。Multi-Head Attention 就是把 Q/K/V 投影到多个不同的子空间比如 8 个或 32 个头每组独立计算注意力最后把所有头的输出拼接起来。每个头可以专注于捕捉不同类型的语言关联整体上表达能力更强。位置编码注入顺序信息Self-Attention 有一个天然的缺陷它的计算是对称的不考虑词的顺序。「我打你」和「你打我」对 Attention 来说可能得到一样的结果因为它只看哪些词相关不看谁在前谁在后。所以需要显式地给每个 token 注入位置信息这就是位置编码。具体的位置编码方案有 sin/cos、RoPE、ALiBi 等多种选择每种各有不同的设计哲学和长上下文外推能力是一个独立的研究方向。本节只需要知道 Transformer 是通过加上位置编码来让模型感知词序的就够了。前馈网络FFN的作用除了注意力层每个 Transformer 块里还有一个前馈网络Feed-Forward Network结构是两层全连接加一个激活函数。FFN 对每个位置独立地做非线性变换补充注意力层学不到的信息注意力层本质上是线性加权FFN 引入非线性。研究表明 FFN 层储存了大量的「事实知识」可以理解为模型的「记忆仓库」。Encoder-only、Decoder-only 和 Encoder-Decoder 三种架构理解了 Attention 的基本机制可以解释这三种架构的区别。Encoder-only以 BERT 为代表每个 token 可以双向关注序列中所有其他 token没有遮蔽。这种双向理解能力让 Encoder 非常擅长「理解任务」比如文本分类、命名实体识别、语义相似度计算。预训练目标是 MLM掩码语言模型随机遮住一些词让模型预测。Decoder-only以 GPT/Claude/Qwen 为代表使用因果掩码Causal Mask每个 token 只能关注它前面的 token不能「提前看到」后面的内容。这种单向设计天然适合文本生成预训练目标是「预测下一个 token」CLM目标统一而强大。现在几乎所有大语言模型都是这个架构。Encoder-Decoder以 T5、BART 为代表Encoder 双向理解输入Decoder 单向生成输出Decoder 通过 Cross-Attention 读取 Encoder 的输出。这种架构适合「输入和输出是不同的文本」的任务比如翻译、摘要、问答。但预训练目标相对复杂超大规模训练不如 Decoder-only 简洁。为什么 Decoder-only 赢了现代通用生成式大模型为什么大多选择 Decoder-only 架构这是面试里最容易被追问的点。根本原因是「预测下一个 token」这个目标极其统一。所有类型的任务问答、写作、推理、代码生成、翻译都可以统一表达成「续写」这一件事不需要区分「这是理解任务」还是「那是生成任务」一套训练目标搞定一切。更关键的是这个目标可以直接在海量无标注文本上做自监督训练。互联网上的大量公开文本天然可以构造成训练样本不需要像传统监督任务那样逐条人工标注。这一点是 BERT 那种 MLM 目标做不到的MLM 也是无标注但训练效率不如 CLM 适合 scale up。最厉害的是随着模型规模增大这个简单目标下涌现出的能力越来越强。模型从「会续写文本」开始逐渐学会数学、推理、代码、跨语言迁移……这些能力都是「预测下一个 token」这个目标在足够大规模下自然涌现的。所有这些特性加在一起使得 Decoder-only 架构在大规模生成式预训练时代取得了压倒性的优势。Encoder-only 和 Encoder-Decoder 这两种架构并没有消失它们在检索、分类、嵌入、翻译、摘要等场景仍然有价值只是如果目标是做一个通用对话和生成模型Decoder-only 更容易 scale up也更符合「一个模型续写所有任务」的统一接口。 面试总结回到开头那段对话问到 Transformer 架构最重要的是先把RNN 的两个致命缺陷讲清楚因为这是 Transformer 出现的动机。RNN 顺序计算无法并行训练慢 长距离梯度消失看不到远处这两个问题在序列稍长就会致命。接下来讲 Self-Attention 怎么解决的。每个 token 通过 Q、K、V 三个独立的线性投影变换得到查询、键、值向量然后用 Q 去和所有 K 做点积算注意力分数按分数加权聚合所有 V。这一段能讲到「Q/K/V 是从同一个 X 通过三个独立矩阵投影得到的」「除以 √d_k 是为了防止点积过大让 softmax 变 one-hot 导致梯度消失」这两个细节就比一般候选人深刻一层了。最关键的一句话是讲清为什么 Decoder-only 赢了。「预测下一个 token」这个目标极其统一所有 NLP 任务都能用它表达可以直接在海量无标注文本上做自监督训练规模越大涌现的能力越强。这种「目标统一 数据规模 涌现」的组合让 Decoder-only 在大模型时代完胜。如果还想再加分可以提一句「FFN 层储存了大量事实知识可以理解为模型的『记忆仓库』」这种从可解释性角度看 Transformer 的视角。能讲到这一层面试官就知道你不是只在背架构图是真的理解了 Transformer 的设计哲学。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
面试官来讲讲 Transformer 架构的基本原理Encoder 和 Decoder 是什么♂️我Transformer 是 Google 提的一个新架构核心是 Attention效果比 RNN 好很多。Encoder 是编码器Decoder 是解码器。面试官……「编码器」「解码器」是中文翻译我问的是它们具体在做什么不是字面意思。再说Attention 凭什么比 RNN 好RNN 到底有什么致命缺陷♂️我哦哦应该是 RNN 太慢了Attention 能并行计算面试官方向对了一半。但你只说了「快」没说「准」。RNN 还有一个更致命的问题长距离信息会衰减第 1 个词的信息传到第 800 个词基本就没了。Attention 怎么解决这个问题的能讲清楚吗♂️我呃……Attention 让每个词都能看到所有其他词面试官勉强能说出来。那再问一个BERT 用的是 Encoder-onlyGPT 用的是 Decoder-only。为什么现在主流大模型GPT、Claude、Qwen全部选择了 Decoder-only这种架构选型背后的原因你能讲清楚吗♂️我呃……面试官典型的「知道有但讲不清」。Decoder-only 赢的根本原因是「预测下一个 token」这个训练目标极其统一所有 NLP 任务都能用它表达。这种「为什么 X 赢了 Y」的演进逻辑搞不清楚去面试就是被怼。回去补一下。这几个反问串起来其实就是一条主线Transformer 这道题想听的不是「Attention is all you need」这种口号而是 RNN 卡在哪两点、Attention 怎么把这两点都破了、三种架构变体打了一圈为什么是 Decoder-only 赢到现在。 简要回答我理解 Transformer 最核心的创新是 Self-Attention让每个 token 都能直接和序列里任意其他位置建立联系一次性并行计算彻底解决了 RNN 顺序计算慢、长距离信息衰减的两个老问题。理解 Encoder 和 Decoder 的区别时我用这个角度Encoder 是双向的每个词能同时看前后文适合做「理解」类任务Decoder 是单向的只能看前面的词天然适合「生成」任务。至于为什么现代大模型GPT、Claude、Qwen都选 Decoder-only核心原因是「预测下一个 token」这个训练目标极其统一、可以直接在海量无标注文本上做自监督学习规模越大涌现出的能力越强。 详细解析Transformer 之前RNN 的致命缺陷在 Transformer 出现之前处理序列数据的主流方法是 RNN循环神经网络及其变体LSTM、GRU。RNN 的问题有两个而且都是致命的。第一个是顺序计算无法并行。RNN 处理序列的方式是从左到右逐个处理每个词第 N 步必须等第 N-1 步计算完才能开始无法利用 GPU 的并行计算能力。这导致训练大型 RNN 极慢。第二个是长距离梯度消失。当序列很长时比如 1000 个词RNN 理论上能记住早期的信息但实践中梯度在反向传播时会指数级衰减网络很难学习到「第 1 个词和第 800 个词之间的关系」。LSTM 通过门控机制有所缓解但根本问题没解决。2017 年 Google 在论文《Attention is All You Need》里提出了 Transformer用一个全新的架构一举解决了这两个问题。Self-Attention 的核心直觉Self-Attention自注意力的核心思路是让序列中的每个 token 都能直接关注序列中任意其他位置的 token计算出「我和其他位置的相关程度」然后根据相关程度加权聚合其他位置的信息。这里有三个关键向量QQuery查询代表「我想找什么」KKey键代表「我有什么标签」VValue值代表「我的实际内容」。可以用图书馆检索来类比你有一个搜索关键词Q图书馆里每本书都有标签K和内容V。注意力机制就是用你的关键词Q去匹配每本书的标签K计算出相似度分数然后按照分数的权重把书的内容V加权求和得到你的搜索结果。Q/K/V 是怎么从输入变换得到的很多人讲 Self-Attention 容易卡在「Q/K/V 是从哪儿冒出来的」这一步。其实 Q/K/V 不是模型「凭空生成」的而是把输入 embedding 通过三个独立的线性投影矩阵W_Q、W_K、W_V 算出来的# 假设输入 X 是 (序列长度 N, embedding 维度 d_model)# W_Q, W_K, W_V 都是可训练参数矩阵形状 (d_model, d_k)Q X W_Q # 形状 (N, d_k)每个 token 都有自己的 Query 向量K X W_K # 形状 (N, d_k)每个 token 都有自己的 Key 向量V X W_V # 形状 (N, d_v)每个 token 都有自己的 Value 向量  这一步就是面试里常被追问的「**Q/K/V 是怎么得到的**」。理解的时候有几个关键点要抓住。 最关键的一点是 Q/K/V 都是**从同一个输入 X 算出来**的。也就是说输入既要扮演「提问者」Q也要扮演「被查者」K V这就是「**自**注意力」里那个「自」字的含义区别于 Encoder-Decoder 架构里 Cross-Attention 那种「Q 来自一边、K/V 来自另一边」的形式。 然后 W\_Q、W\_K、W\_V 是三个**独立学习**的矩阵。这是个容易被忽略的细节但很重要。如果让 Q/K/V 都直接等于 X 不做变换模型就没法学到「该从什么角度提问」「该用什么标签匹配」「该返回什么内容」这种细致的差异。三个独立投影让模型有 3 倍的自由度去学习这种角度上的差异模型容量大幅提升。 还有一个工程细节是投影维度 d\_k 通常等于 d\_model / HH 是头数。比如 d\_model512、H8 时d\_k64。这样做的目的是让多头总参数量和单头版本基本一致不增加额外的计算开销。 到这里Q/K/V 三个向量就准备好了可以代入注意力公式 plaintext Attention(Q, K, V) softmax(Q · K^T / √d_k) · V为什么要除以 √d_k缩放点积的数学直觉公式里的/√d_k这一步常被叫做Scaled Dot-Product Attention缩放点积注意力。这个 √d_k 不是随便加的背后有具体的数学动机。直觉上的问题是这样的当 d_k 很大时比如 d_k128Q 和 K 都是 128 维的向量它们的点积是 128 个数相加。假设 Q 和 K 的每一维都是均值 0、方差 1 的随机数那么点积 Q·K 的方差就是 d_k128标准差是 √128 ≈ 11.3。这意味着点积的数值会散布在 -30 到 30 这种很大的范围。然后这些数过 softmax 会发生什么softmax 对极端大的输入特别敏感最大的那个数对应的概率会接近 1其他数的概率会接近 0输出几乎变成 one-hot 分布。one-hot 分布的问题是梯度消失。softmax 的梯度公式里有p · (1-p)项p 接近 0 或 1 时梯度都接近 0。整个 Attention 层的反向传播信号被压扁模型训不起来。除以 √d_k 之后点积的方差被压回 1softmax 输出分布合理梯度能正常传播。那能不能用其他方案替代 √d_k理论上可以但 √d_k 是数学上最自然的选择。业界确实尝试过几种替代方案。一种是用 Layer Norm 来归一化比如某些 Attention 变体Pre-LN Transformer会在 Attention 之前先把输入归一化到固定范围这样后续的点积值天然就不会爆炸。但严格来说这是「在 Attention 之前做归一化」不是真的替换 √d_k 本身。另一种是让模型自己学一个 scaling 参数用一个可学习的标量代替 √d_k。实测效果和 √d_k 差不多但增加了可学习参数反而不如固定常数简洁。还有一种早期方案是直接限制 d_k 很小比如 d_k8让点积自然不会爆炸但这等于直接限制了模型的容量不划算。实践中所有主流 Transformer 实现GPT、LLaMA、Qwen 等都用 √d_k没有改。这是一个被 8 年实践验证的「简单且数学上合理」的选择。回到主线除以 √d_k 之后softmax 的输出就是稳定的注意力权重再用这些权重对 V 做加权求和就得到了 Self-Attention 的最终输出。整个过程对序列中所有位置的计算是可以并行的完美解决了 RNN 的并行问题而且每对位置之间都有直接连接通过注意力分数不存在长距离信息衰减的问题。Multi-Head Attention多角度观察单组 Q/K/V 只能学习到一种「关联关系」但语言中的关联是多维度的「我」和「吃」是主谓关系「苹果」和「吃」是宾动关系「苹果」和前文的「苹果树」是指代关系这些不同类型的关联需要不同的「注意力头」来捕捉。Multi-Head Attention 就是把 Q/K/V 投影到多个不同的子空间比如 8 个或 32 个头每组独立计算注意力最后把所有头的输出拼接起来。每个头可以专注于捕捉不同类型的语言关联整体上表达能力更强。位置编码注入顺序信息Self-Attention 有一个天然的缺陷它的计算是对称的不考虑词的顺序。「我打你」和「你打我」对 Attention 来说可能得到一样的结果因为它只看哪些词相关不看谁在前谁在后。所以需要显式地给每个 token 注入位置信息这就是位置编码。具体的位置编码方案有 sin/cos、RoPE、ALiBi 等多种选择每种各有不同的设计哲学和长上下文外推能力是一个独立的研究方向。本节只需要知道 Transformer 是通过加上位置编码来让模型感知词序的就够了。前馈网络FFN的作用除了注意力层每个 Transformer 块里还有一个前馈网络Feed-Forward Network结构是两层全连接加一个激活函数。FFN 对每个位置独立地做非线性变换补充注意力层学不到的信息注意力层本质上是线性加权FFN 引入非线性。研究表明 FFN 层储存了大量的「事实知识」可以理解为模型的「记忆仓库」。Encoder-only、Decoder-only 和 Encoder-Decoder 三种架构理解了 Attention 的基本机制可以解释这三种架构的区别。Encoder-only以 BERT 为代表每个 token 可以双向关注序列中所有其他 token没有遮蔽。这种双向理解能力让 Encoder 非常擅长「理解任务」比如文本分类、命名实体识别、语义相似度计算。预训练目标是 MLM掩码语言模型随机遮住一些词让模型预测。Decoder-only以 GPT/Claude/Qwen 为代表使用因果掩码Causal Mask每个 token 只能关注它前面的 token不能「提前看到」后面的内容。这种单向设计天然适合文本生成预训练目标是「预测下一个 token」CLM目标统一而强大。现在几乎所有大语言模型都是这个架构。Encoder-Decoder以 T5、BART 为代表Encoder 双向理解输入Decoder 单向生成输出Decoder 通过 Cross-Attention 读取 Encoder 的输出。这种架构适合「输入和输出是不同的文本」的任务比如翻译、摘要、问答。但预训练目标相对复杂超大规模训练不如 Decoder-only 简洁。为什么 Decoder-only 赢了现代通用生成式大模型为什么大多选择 Decoder-only 架构这是面试里最容易被追问的点。根本原因是「预测下一个 token」这个目标极其统一。所有类型的任务问答、写作、推理、代码生成、翻译都可以统一表达成「续写」这一件事不需要区分「这是理解任务」还是「那是生成任务」一套训练目标搞定一切。更关键的是这个目标可以直接在海量无标注文本上做自监督训练。互联网上的大量公开文本天然可以构造成训练样本不需要像传统监督任务那样逐条人工标注。这一点是 BERT 那种 MLM 目标做不到的MLM 也是无标注但训练效率不如 CLM 适合 scale up。最厉害的是随着模型规模增大这个简单目标下涌现出的能力越来越强。模型从「会续写文本」开始逐渐学会数学、推理、代码、跨语言迁移……这些能力都是「预测下一个 token」这个目标在足够大规模下自然涌现的。所有这些特性加在一起使得 Decoder-only 架构在大规模生成式预训练时代取得了压倒性的优势。Encoder-only 和 Encoder-Decoder 这两种架构并没有消失它们在检索、分类、嵌入、翻译、摘要等场景仍然有价值只是如果目标是做一个通用对话和生成模型Decoder-only 更容易 scale up也更符合「一个模型续写所有任务」的统一接口。 面试总结回到开头那段对话问到 Transformer 架构最重要的是先把RNN 的两个致命缺陷讲清楚因为这是 Transformer 出现的动机。RNN 顺序计算无法并行训练慢 长距离梯度消失看不到远处这两个问题在序列稍长就会致命。接下来讲 Self-Attention 怎么解决的。每个 token 通过 Q、K、V 三个独立的线性投影变换得到查询、键、值向量然后用 Q 去和所有 K 做点积算注意力分数按分数加权聚合所有 V。这一段能讲到「Q/K/V 是从同一个 X 通过三个独立矩阵投影得到的」「除以 √d_k 是为了防止点积过大让 softmax 变 one-hot 导致梯度消失」这两个细节就比一般候选人深刻一层了。最关键的一句话是讲清为什么 Decoder-only 赢了。「预测下一个 token」这个目标极其统一所有 NLP 任务都能用它表达可以直接在海量无标注文本上做自监督训练规模越大涌现的能力越强。这种「目标统一 数据规模 涌现」的组合让 Decoder-only 在大模型时代完胜。如果还想再加分可以提一句「FFN 层储存了大量事实知识可以理解为模型的『记忆仓库』」这种从可解释性角度看 Transformer 的视角。能讲到这一层面试官就知道你不是只在背架构图是真的理解了 Transformer 的设计哲学。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
抖音大模型二面:讲讲 Transformer 架构的基本原理?Encoder 和 Decoder 是什么?
发布时间:2026/6/9 2:05:21
面试官来讲讲 Transformer 架构的基本原理Encoder 和 Decoder 是什么♂️我Transformer 是 Google 提的一个新架构核心是 Attention效果比 RNN 好很多。Encoder 是编码器Decoder 是解码器。面试官……「编码器」「解码器」是中文翻译我问的是它们具体在做什么不是字面意思。再说Attention 凭什么比 RNN 好RNN 到底有什么致命缺陷♂️我哦哦应该是 RNN 太慢了Attention 能并行计算面试官方向对了一半。但你只说了「快」没说「准」。RNN 还有一个更致命的问题长距离信息会衰减第 1 个词的信息传到第 800 个词基本就没了。Attention 怎么解决这个问题的能讲清楚吗♂️我呃……Attention 让每个词都能看到所有其他词面试官勉强能说出来。那再问一个BERT 用的是 Encoder-onlyGPT 用的是 Decoder-only。为什么现在主流大模型GPT、Claude、Qwen全部选择了 Decoder-only这种架构选型背后的原因你能讲清楚吗♂️我呃……面试官典型的「知道有但讲不清」。Decoder-only 赢的根本原因是「预测下一个 token」这个训练目标极其统一所有 NLP 任务都能用它表达。这种「为什么 X 赢了 Y」的演进逻辑搞不清楚去面试就是被怼。回去补一下。这几个反问串起来其实就是一条主线Transformer 这道题想听的不是「Attention is all you need」这种口号而是 RNN 卡在哪两点、Attention 怎么把这两点都破了、三种架构变体打了一圈为什么是 Decoder-only 赢到现在。 简要回答我理解 Transformer 最核心的创新是 Self-Attention让每个 token 都能直接和序列里任意其他位置建立联系一次性并行计算彻底解决了 RNN 顺序计算慢、长距离信息衰减的两个老问题。理解 Encoder 和 Decoder 的区别时我用这个角度Encoder 是双向的每个词能同时看前后文适合做「理解」类任务Decoder 是单向的只能看前面的词天然适合「生成」任务。至于为什么现代大模型GPT、Claude、Qwen都选 Decoder-only核心原因是「预测下一个 token」这个训练目标极其统一、可以直接在海量无标注文本上做自监督学习规模越大涌现出的能力越强。 详细解析Transformer 之前RNN 的致命缺陷在 Transformer 出现之前处理序列数据的主流方法是 RNN循环神经网络及其变体LSTM、GRU。RNN 的问题有两个而且都是致命的。第一个是顺序计算无法并行。RNN 处理序列的方式是从左到右逐个处理每个词第 N 步必须等第 N-1 步计算完才能开始无法利用 GPU 的并行计算能力。这导致训练大型 RNN 极慢。第二个是长距离梯度消失。当序列很长时比如 1000 个词RNN 理论上能记住早期的信息但实践中梯度在反向传播时会指数级衰减网络很难学习到「第 1 个词和第 800 个词之间的关系」。LSTM 通过门控机制有所缓解但根本问题没解决。2017 年 Google 在论文《Attention is All You Need》里提出了 Transformer用一个全新的架构一举解决了这两个问题。Self-Attention 的核心直觉Self-Attention自注意力的核心思路是让序列中的每个 token 都能直接关注序列中任意其他位置的 token计算出「我和其他位置的相关程度」然后根据相关程度加权聚合其他位置的信息。这里有三个关键向量QQuery查询代表「我想找什么」KKey键代表「我有什么标签」VValue值代表「我的实际内容」。可以用图书馆检索来类比你有一个搜索关键词Q图书馆里每本书都有标签K和内容V。注意力机制就是用你的关键词Q去匹配每本书的标签K计算出相似度分数然后按照分数的权重把书的内容V加权求和得到你的搜索结果。Q/K/V 是怎么从输入变换得到的很多人讲 Self-Attention 容易卡在「Q/K/V 是从哪儿冒出来的」这一步。其实 Q/K/V 不是模型「凭空生成」的而是把输入 embedding 通过三个独立的线性投影矩阵W_Q、W_K、W_V 算出来的# 假设输入 X 是 (序列长度 N, embedding 维度 d_model)# W_Q, W_K, W_V 都是可训练参数矩阵形状 (d_model, d_k)Q X W_Q # 形状 (N, d_k)每个 token 都有自己的 Query 向量K X W_K # 形状 (N, d_k)每个 token 都有自己的 Key 向量V X W_V # 形状 (N, d_v)每个 token 都有自己的 Value 向量  这一步就是面试里常被追问的「**Q/K/V 是怎么得到的**」。理解的时候有几个关键点要抓住。 最关键的一点是 Q/K/V 都是**从同一个输入 X 算出来**的。也就是说输入既要扮演「提问者」Q也要扮演「被查者」K V这就是「**自**注意力」里那个「自」字的含义区别于 Encoder-Decoder 架构里 Cross-Attention 那种「Q 来自一边、K/V 来自另一边」的形式。 然后 W\_Q、W\_K、W\_V 是三个**独立学习**的矩阵。这是个容易被忽略的细节但很重要。如果让 Q/K/V 都直接等于 X 不做变换模型就没法学到「该从什么角度提问」「该用什么标签匹配」「该返回什么内容」这种细致的差异。三个独立投影让模型有 3 倍的自由度去学习这种角度上的差异模型容量大幅提升。 还有一个工程细节是投影维度 d\_k 通常等于 d\_model / HH 是头数。比如 d\_model512、H8 时d\_k64。这样做的目的是让多头总参数量和单头版本基本一致不增加额外的计算开销。 到这里Q/K/V 三个向量就准备好了可以代入注意力公式 plaintext Attention(Q, K, V) softmax(Q · K^T / √d_k) · V为什么要除以 √d_k缩放点积的数学直觉公式里的/√d_k这一步常被叫做Scaled Dot-Product Attention缩放点积注意力。这个 √d_k 不是随便加的背后有具体的数学动机。直觉上的问题是这样的当 d_k 很大时比如 d_k128Q 和 K 都是 128 维的向量它们的点积是 128 个数相加。假设 Q 和 K 的每一维都是均值 0、方差 1 的随机数那么点积 Q·K 的方差就是 d_k128标准差是 √128 ≈ 11.3。这意味着点积的数值会散布在 -30 到 30 这种很大的范围。然后这些数过 softmax 会发生什么softmax 对极端大的输入特别敏感最大的那个数对应的概率会接近 1其他数的概率会接近 0输出几乎变成 one-hot 分布。one-hot 分布的问题是梯度消失。softmax 的梯度公式里有p · (1-p)项p 接近 0 或 1 时梯度都接近 0。整个 Attention 层的反向传播信号被压扁模型训不起来。除以 √d_k 之后点积的方差被压回 1softmax 输出分布合理梯度能正常传播。那能不能用其他方案替代 √d_k理论上可以但 √d_k 是数学上最自然的选择。业界确实尝试过几种替代方案。一种是用 Layer Norm 来归一化比如某些 Attention 变体Pre-LN Transformer会在 Attention 之前先把输入归一化到固定范围这样后续的点积值天然就不会爆炸。但严格来说这是「在 Attention 之前做归一化」不是真的替换 √d_k 本身。另一种是让模型自己学一个 scaling 参数用一个可学习的标量代替 √d_k。实测效果和 √d_k 差不多但增加了可学习参数反而不如固定常数简洁。还有一种早期方案是直接限制 d_k 很小比如 d_k8让点积自然不会爆炸但这等于直接限制了模型的容量不划算。实践中所有主流 Transformer 实现GPT、LLaMA、Qwen 等都用 √d_k没有改。这是一个被 8 年实践验证的「简单且数学上合理」的选择。回到主线除以 √d_k 之后softmax 的输出就是稳定的注意力权重再用这些权重对 V 做加权求和就得到了 Self-Attention 的最终输出。整个过程对序列中所有位置的计算是可以并行的完美解决了 RNN 的并行问题而且每对位置之间都有直接连接通过注意力分数不存在长距离信息衰减的问题。Multi-Head Attention多角度观察单组 Q/K/V 只能学习到一种「关联关系」但语言中的关联是多维度的「我」和「吃」是主谓关系「苹果」和「吃」是宾动关系「苹果」和前文的「苹果树」是指代关系这些不同类型的关联需要不同的「注意力头」来捕捉。Multi-Head Attention 就是把 Q/K/V 投影到多个不同的子空间比如 8 个或 32 个头每组独立计算注意力最后把所有头的输出拼接起来。每个头可以专注于捕捉不同类型的语言关联整体上表达能力更强。位置编码注入顺序信息Self-Attention 有一个天然的缺陷它的计算是对称的不考虑词的顺序。「我打你」和「你打我」对 Attention 来说可能得到一样的结果因为它只看哪些词相关不看谁在前谁在后。所以需要显式地给每个 token 注入位置信息这就是位置编码。具体的位置编码方案有 sin/cos、RoPE、ALiBi 等多种选择每种各有不同的设计哲学和长上下文外推能力是一个独立的研究方向。本节只需要知道 Transformer 是通过加上位置编码来让模型感知词序的就够了。前馈网络FFN的作用除了注意力层每个 Transformer 块里还有一个前馈网络Feed-Forward Network结构是两层全连接加一个激活函数。FFN 对每个位置独立地做非线性变换补充注意力层学不到的信息注意力层本质上是线性加权FFN 引入非线性。研究表明 FFN 层储存了大量的「事实知识」可以理解为模型的「记忆仓库」。Encoder-only、Decoder-only 和 Encoder-Decoder 三种架构理解了 Attention 的基本机制可以解释这三种架构的区别。Encoder-only以 BERT 为代表每个 token 可以双向关注序列中所有其他 token没有遮蔽。这种双向理解能力让 Encoder 非常擅长「理解任务」比如文本分类、命名实体识别、语义相似度计算。预训练目标是 MLM掩码语言模型随机遮住一些词让模型预测。Decoder-only以 GPT/Claude/Qwen 为代表使用因果掩码Causal Mask每个 token 只能关注它前面的 token不能「提前看到」后面的内容。这种单向设计天然适合文本生成预训练目标是「预测下一个 token」CLM目标统一而强大。现在几乎所有大语言模型都是这个架构。Encoder-Decoder以 T5、BART 为代表Encoder 双向理解输入Decoder 单向生成输出Decoder 通过 Cross-Attention 读取 Encoder 的输出。这种架构适合「输入和输出是不同的文本」的任务比如翻译、摘要、问答。但预训练目标相对复杂超大规模训练不如 Decoder-only 简洁。为什么 Decoder-only 赢了现代通用生成式大模型为什么大多选择 Decoder-only 架构这是面试里最容易被追问的点。根本原因是「预测下一个 token」这个目标极其统一。所有类型的任务问答、写作、推理、代码生成、翻译都可以统一表达成「续写」这一件事不需要区分「这是理解任务」还是「那是生成任务」一套训练目标搞定一切。更关键的是这个目标可以直接在海量无标注文本上做自监督训练。互联网上的大量公开文本天然可以构造成训练样本不需要像传统监督任务那样逐条人工标注。这一点是 BERT 那种 MLM 目标做不到的MLM 也是无标注但训练效率不如 CLM 适合 scale up。最厉害的是随着模型规模增大这个简单目标下涌现出的能力越来越强。模型从「会续写文本」开始逐渐学会数学、推理、代码、跨语言迁移……这些能力都是「预测下一个 token」这个目标在足够大规模下自然涌现的。所有这些特性加在一起使得 Decoder-only 架构在大规模生成式预训练时代取得了压倒性的优势。Encoder-only 和 Encoder-Decoder 这两种架构并没有消失它们在检索、分类、嵌入、翻译、摘要等场景仍然有价值只是如果目标是做一个通用对话和生成模型Decoder-only 更容易 scale up也更符合「一个模型续写所有任务」的统一接口。 面试总结回到开头那段对话问到 Transformer 架构最重要的是先把RNN 的两个致命缺陷讲清楚因为这是 Transformer 出现的动机。RNN 顺序计算无法并行训练慢 长距离梯度消失看不到远处这两个问题在序列稍长就会致命。接下来讲 Self-Attention 怎么解决的。每个 token 通过 Q、K、V 三个独立的线性投影变换得到查询、键、值向量然后用 Q 去和所有 K 做点积算注意力分数按分数加权聚合所有 V。这一段能讲到「Q/K/V 是从同一个 X 通过三个独立矩阵投影得到的」「除以 √d_k 是为了防止点积过大让 softmax 变 one-hot 导致梯度消失」这两个细节就比一般候选人深刻一层了。最关键的一句话是讲清为什么 Decoder-only 赢了。「预测下一个 token」这个目标极其统一所有 NLP 任务都能用它表达可以直接在海量无标注文本上做自监督训练规模越大涌现的能力越强。这种「目标统一 数据规模 涌现」的组合让 Decoder-only 在大模型时代完胜。如果还想再加分可以提一句「FFN 层储存了大量事实知识可以理解为模型的『记忆仓库』」这种从可解释性角度看 Transformer 的视角。能讲到这一层面试官就知道你不是只在背架构图是真的理解了 Transformer 的设计哲学。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】





)
)

)








