 一、向量数据库在 RAG 流程中的位置回顾 RAG 的完整流程向量数据库承担着存储与检索的核心角色将私有知识文档、手册、代码库等分片后通过 Embedding 模型转为向量存入向量数据库。用户提问时将问题同样转为向量。在向量数据库中执行相似性搜索找出与问题语义最接近的 Top-K 个文档块。将检索到的上下文和用户问题一起传给大模型生成有据可依的回答。Spring AI 提供了统一的VectorStore接口屏蔽底层差异官方文档https://docs.spring.io/spring-ai/reference/api/vectordbs.html 列出了所有支持的实现。本文聚焦于可私有化部署的向量数据库排除仅云服务的产品如 Pinecone确保企业敏感数据不离开内部环境。二、选型的六个核心维度向量数据库选型没有最好只有最合适。以下六个维度是评估重点2.1 部署复杂度部署和运维门槛直接影响团队能否快速落地。Chroma可在内存中直接运行适合原型阶段pgvector只需在现有 PostgreSQL 上CREATE EXTENSION vectorMilvus则需要容器化部署和专业运维能力。部署复杂度越高后期投入越大。2.2 检索性能硬指标——查询延迟单次响应速度和吞吐量并发 QPS。多数向量索引常驻内存内存消耗直接决定硬件成本。HNSW 索引查询快但构建慢且内存占用高IVF 索引用内存更少但召回率略低。2.3 可扩展性数据量在百万级以下几乎所有数据库都能胜任。当规模增长到千万甚至亿级时Milvus的分布式存算分离架构优势明显pgvector则受限于 PostgreSQL 单机瓶颈Qdrant提供中等规模的集群能力。2.4 集成便利性与现有技术栈兼容是选型的实用智慧。如果已有 PostgreSQL直接用pgvector零额外组件已有 Elasticsearch 集群直接启用dense_vector字段即可如果团队以 Java/Spring 为主优先看 Spring AI 官方提供 Starter 的产品。2.5 高级特性元数据过滤是生产环境的硬门槛——如果无法按文档来源、版本号、日期等过滤检索结果不可控基本可以排除。混合检索BM25 关键词 向量语义能将两种检索优势互补也是从能用到好用的关键。2.6 社区活跃度活跃的社区意味着持续的 bug 修复、性能优化和丰富的踩坑经验。截至 2025 年Milvus36K GitHub Stars和 pgvector12K Stars生态最为成熟。三、候选数据库详解以下逐一分析可私有化部署的五款主流向量数据库每款均基于 Spring AI 1.0 官方 Starter 给出 Maven 依赖和 YAML 配置示例并使用《仙逆》片段作为演示数据。3.1 PGVector —— 就地取材、SQL 向量合二为一定位PostgreSQL 扩展CREATE EXTENSION vector即可让现有关系型数据库拥有向量能力。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-pgvector/artifactId/dependencydependency groupIdorg.springframework.boot/groupId artifactIdspring-boot-starter-jdbc/artifactId/dependencydependency groupIdorg.postgresql/groupId artifactIdpostgresql/artifactId/dependencyapplication.ymlspring: datasource: url:jdbc: postgresql://localhost:5432/xianni_rag username: postgres password: postgresai: vectorstore: pgvector: index-type: HNSW # HNSW | IVFFLAT distance-type: COSINE_DISTANCE # COSINE_DISTANCE | EUCLIDEAN_DISTANCE | NEGATIVE_INNER_PRODUCT dimensions: 1024 # 须与 Embedding 模型输出维度一致 initialize-schema: true # 首次启动自动建表使用示例——存储并检索《仙逆》片段// 注入 Spring AI 自动配置的 VectorStoreAutowiredprivate VectorStore vectorStore;// 写入将《仙逆》片段写入向量库 ListDocument documents List.of( new Document(王林自封修为在落月村化身木匠陪伴儿子王平七十二年。, Map.of(character, 王林, chapter, 二次化凡)), new Document(雷道子看穿王平的怨婴体质要拿他炼器触碰了王林的逆鳞。, Map.of(character, 雷道子, chapter, 二次化凡)), new Document(司徒南被封印在天逆珠中万年性格豪爽多次危急时出手救王林。, Map.of(character, 司徒南, chapter, 仙罡大陆)), new Document(李慕婉结婴失败身殒残魂被保存在天逆珠中王林耗尽千年将其复活。, Map.of(character, 李慕婉, chapter, 全文主线)));vectorStore.add(documents);// 检索查询王林如何在落月村陪伴儿子 SearchRequest request SearchRequest.builder() .query(王林如何在落月村陪伴儿子) .topK(3) .similarityThreshold(0.7) .filterExpression(character 王林) // 按人物过滤 .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林自封修为在落月村化身木匠陪伴儿子王平七十二年。pgvector 的核心优势在于 SQL 向量的混合查询——你可以写一条 SQL 同时做结构化过滤、全文检索和向量相似度排序这在需要复杂业务逻辑的场景中无可替代-- 查询二次化凡章节中与王平怨气语义最接近的 5 个片段SELECT content, 1 - (embedding query_embedding) AS similarityFROM vector_storeWHERE metadata-chapter 二次化凡 -- 结构化过滤 AND 1 - (embedding query_embedding) 0.7ORDER BY embedding query_embeddingLIMIT 5; 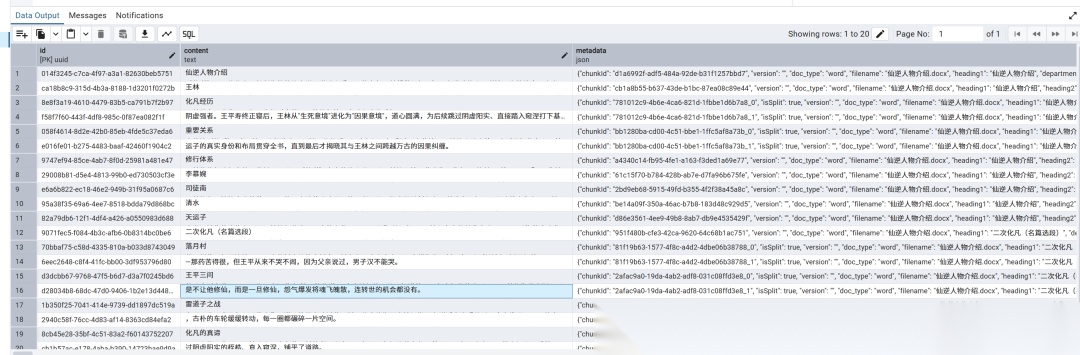 检索结果 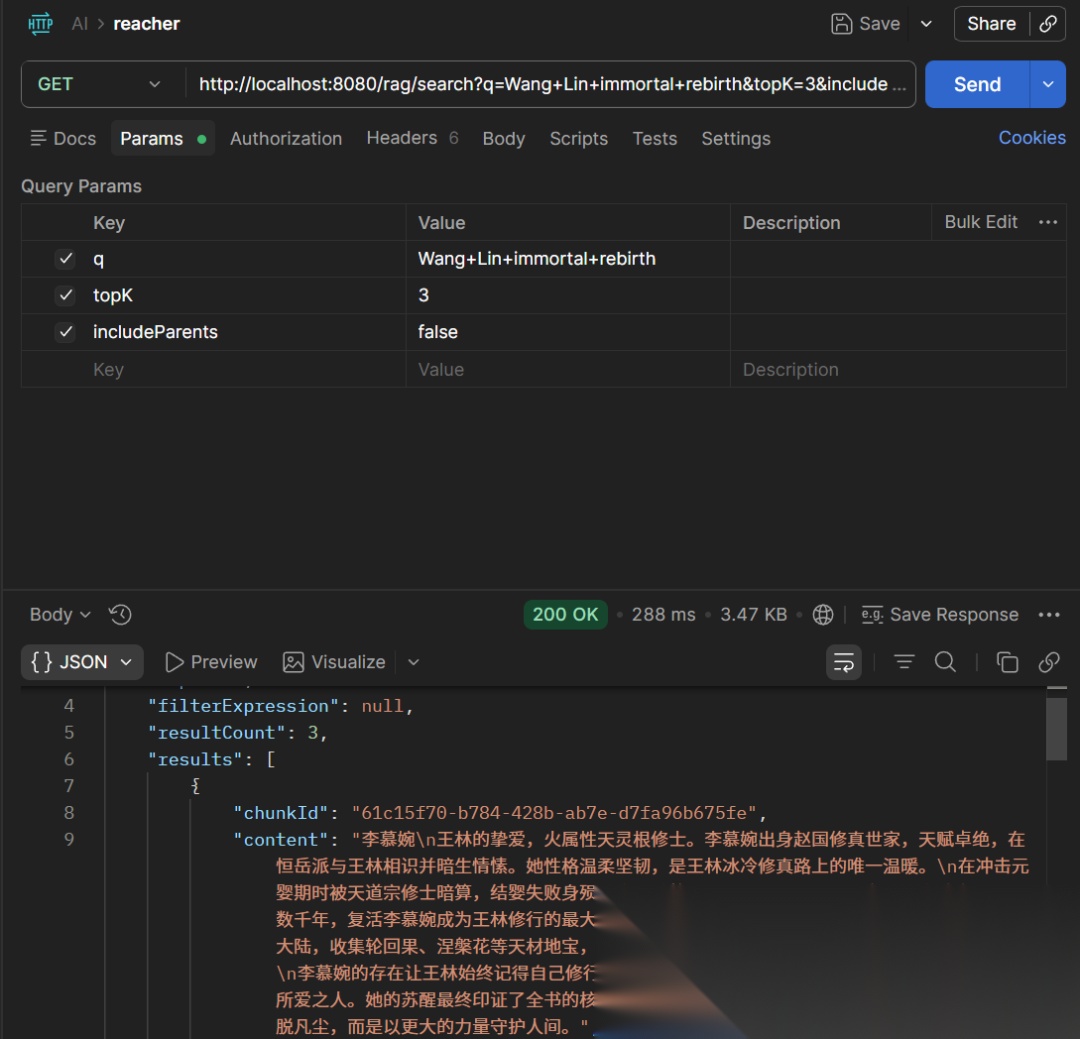 **特点总结** | 维度 | 评价 | | --- | --- | | 部署复杂度 | 低——已有 PG 零成本CREATE EXTENSION 搞定 | | 数据规模 | 百万~千万级亿级以上性能下降明显 | | 索引算法 | HNSW、IVFFlat | | 混合检索 | 借助 PG 全文检索 JOIN 灵活组合 | | 元数据过滤 | 完整支持SQL WHERE 级别 | | 适用场景 | 已有 PG 的团队、中小规模 RAG、需要 SQL 混合查询的业务 | | Spring AI Starter | spring-ai-starter-vector-store-pgvector | --- ### 3.2 Chroma —— 轻量级 AI 原生数据库 **定位**专为 AI 应用设计的轻量向量数据库开箱即用甚至可在内存中运行。 **Maven 依赖** plaintext dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-chroma/artifactId/dependencyapplication.ymlspring: ai: vectorstore: chroma: host: http://localhost:8000 # Chroma 服务地址 collection-name: xianni_knowledge # 集合名称 initialize-schema: true使用示例——用 Chroma 管理《仙逆》人物档案Autowiredprivate VectorStore vectorStore;// 写入《仙逆》人物卡片ListDocument characters List.of( new Document(王林主角资质平平但心智坚韧。顺为凡逆则仙为信念从恒岳派杂役修至踏天之境。, Map.of(type, character_card, importance, main)), new Document(王平养子天生怨婴体质。王林为化解他的怨气自封修为在落月村陪伴他七十二年。, Map.of(type, character_card, importance, key)), new Document(雷道子阴虚境强者看穿王平怨婴真相要拿他炼器被王林以问鼎中期修为越级斩杀。, Map.of(type, character_card, importance, minor)));vectorStore.add(characters);// 搜索——用户问王林自封修为是为了谁ListDocument results vectorStore.similaritySearch( SearchRequest.builder() .query(王林自封修为是为了谁) .topK(2) .build());// 命中王平的人物卡片——王林为化解他的怨气自封修为特点总结维度评价部署复杂度极低——Docker 一行命令支持嵌入/CS 两种模式数据规模小规模十万~百万级不适用高并发生产索引算法HNSW默认混合检索不支持原生混合检索元数据过滤简单支持适用场景原型验证、教学实验、个人项目。生产环境不推荐Spring AI Starterspring-ai-starter-vector-store-chroma3.3 Milvus —— 大规模生产的分布式方案定位云原生分布式向量数据库为十亿级向量检索而生是开源方案中最成熟的专业产品。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-milvus/artifactId/dependencyapplication.ymlspring: ai: vectorstore: milvus: host: localhost port: 19530 database-name: default collection-name: xianni_full_text metric-type: COSINE # COSINE | L2 | IP index-type: IVF_FLAT # IVF_FLAT | HNSW | IVF_SQ8 | IVF_PQ 等 dimensions: 1024 initialize-schema: true使用示例——《仙逆》全量小说检索Autowiredprivate VectorStore vectorStore;// 写入整部《仙逆》的分片示意实际可能是数万个分片ListDocument chapters List.of( new Document(化神先化凡这是化神期的关键一步。他低头看了看自己的双手 这双手曾经沾满鲜血如今却只是在木雕上刻下纹路。, Map.of(volume, 化凡篇, chapter_num, 342)), new Document(王平临终前握住王林的手用最后的力气问爹我到底能不能修道 王林老泪纵横不能……平儿不是爹不让你修……是你修不了啊……, Map.of(volume, 二次化凡, chapter_num, 367)), new Document(王林仰天长笑道心从生死意境蜕变为因果意境。 为后续跳过阴虚阳实、直入窥涅铺平了道路。, Map.of(volume, 二次化凡, chapter_num, 370)));vectorStore.add(chapters);// 检索——用户问王林是怎么悟出因果意境的SearchRequest request SearchRequest.builder() .query(王林是怎么悟出因果意境的) .topK(5) .similarityThreshold(0.75) .filterExpression(volume 二次化凡) .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林在落月村陪伴王平→王平去世→道心蜕变→因果意境 的完整因果链Milvus 检索示例假设《仙逆》全量有 40 万个分片查询因果意境如何悟出Milvus 在 IVF_FLAT 索引下仅需扫描约 5% 的聚类2 万个向量延迟控制在毫秒级。同查询在 pgvector 上如果做到亿级数据量延迟将明显上升。特点总结维度评价部署复杂度高——需容器化Docker Compose/K8s推荐 16GB 内存数据规模十亿级水平扩展索引算法10 种HNSW, IVF_FLAT, IVF_SQ8, IVF_PQ, DiskANN, GPU 加速等混合检索原生支持v2.5 密集向量 BM25 稀疏向量 全文检索元数据过滤完整支持标量索引加速适用场景大规模企业 RAG、推荐系统、图像/视频语义搜索Spring AI Starterspring-ai-starter-vector-store-milvus3.4 Qdrant —— 性能与简洁的平衡定位Rust 实现的高性能向量数据库API 简洁内存效率高兼顾性能与易用性。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-qdrant/artifactId/dependencyapplication.ymlspring: ai: vectorstore: qdrant: host: localhost port: 6334 collection-name: xianni_rag initialize-schema: true使用示例——用 Qdrant 的元数据过滤做精准检索Autowiredprivate VectorStore vectorStore;// 写入《仙逆》战斗场景数据ListDocument battles List.of( new Document(王林以问鼎中期修为迎战阴虚境雷道子。因果意境锁定魂魄 射神车轮转碾碎空间一击斩杀。, Map.of(battle_type, 越级战, winner, 王林, loser, 雷道子)), new Document(司徒南破开天逆珠封印一剑斩灭三位窥涅期修士的联手围杀。, Map.of(battle_type, 碾压局, winner, 司徒南, loser, 窥涅三人组)), new Document(清水仙君在洞府大战中以一敌百剑下无一合之敌。, Map.of(battle_type, 群战, winner, 清水, loser, 洞府联军)));vectorStore.add(battles);// 检索——用户问王林打过的越级战有哪些SearchRequest request SearchRequest.builder() .query(王林打过的越级战有哪些) .topK(5) .filterExpression(winner 王林 battle_type 越级战) .build();ListDocument results vectorStore.similaritySearch(request);// Qdrant 的元数据过滤性能极高——在过滤条件下仍然保持低延迟检索特点总结维度评价部署复杂度中——Docker 单命令Rust 实现资源占用低数据规模中等百万~千万级多节点集群支持索引算法HNSW 为主支持标量/向量量化压缩混合检索稀疏密集向量组合元数据过滤高性能——过滤条件下查询性能下降很小核心优势适用场景中等规模、需要复杂元数据过滤、追求简洁运维的团队Spring AI Starterspring-ai-starter-vector-store-qdrant3.5 Elasticsearch —— 关键词 向量的万能选手定位搜索引擎出身8.0 版本支持dense_vector字段擅长全文检索与向量检索的融合。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-elasticsearch/artifactId/dependencyapplication.ymlspring: elasticsearch: uris: http://localhost:9200ai: vectorstore: elasticsearch: index-name: xianni_rag dimensions: 1024 similarity: cosine # cosine | l2_norm | dot_product initialize-schema: true使用示例——全文 向量混合搜索《仙逆》Autowiredprivate VectorStore vectorStore;// 写入《仙逆》高光片段ListDocument highlights List.of( new Document(顺为凡逆则仙。王林以此信念走过了千年修真路 从恒岳派的杂役做到了一界之主再到踏天。 Map.of(type, 名言, speaker, 旁白)), new Document(王平三次问父亲能不能修道三次被拒绝。 这不是残忍是保护——怨婴一旦修仙怨气爆发便魂飞魄散。 Map.of(type, 名场面, chapter, 王平三问)), new Document(雷道子道破真相那日王林解开封印。问鼎中期的气势如火山爆发 万古枯木从地底破土射神车碾碎虚空。 Map.of(type, 战斗, chapter, 落月村之战)));vectorStore.add(highlights);// Elasticsearch 优势——在 query 中混合关键词匹配 语义相似度// 用户搜索落月村 战斗——落月村命中 BM25战斗命中语义向量SearchRequest request SearchRequest.builder() .query(落月村发生的战斗) .topK(3) .build();ListDocument results vectorStore.similaritySearch(request);// ES 在同一查询中融合 BM25 关键词匹配 向量语义精准定位雷道子之战特点总结维度评价部署复杂度中偏高——JVM 调优、集群管理需经验数据规模中等百万~十亿级依赖 ES 集群扩展索引算法HNSWdense_vector字段混合检索核心优势——原生融合 BM25 向量scoreα×BM25 (1-α)×余弦元数据过滤完整支持倒排索引加持适用场景已有 ELK 的团队、需关键词语义双引擎的场景Spring AI Starterspring-ai-starter-vector-store-elasticsearch四、全方位对比维度PGVectorChromaMilvusQdrantElasticsearch定位PG 扩展轻量 AI 原生分布式专业库高性能简洁搜索引擎向量部署复杂度低极低高中中偏高数据规模百万~千万十万~百万十亿级百万~千万百万~十亿索引算法HNSW, IVFFlatHNSW10 种含 GPUHNSWHNSW混合检索SQL 组合不支持原生部分原生最大优势元数据过滤完整简单完整高性能完整Spring AI StarterpgvectorchromamilvusqdrantelasticsearchLangChain4j 模块langchain4j-pgvectorlangchain4j-chromalangchain4j-milvuslangchain4j-qdrantlangchain4j-elasticsearch适用场景已有PG的中小RAG原型/学习大规模生产中等规模已有ES的混合搜索五、选型决策以下按团队现状给出推荐路径你的情况推荐理由已有 PostgreSQL百万级文档pgvector零新组件SQL JOIN 关联元数据和父块运维零成本已有 Elasticsearch 集群Elasticsearch就地启用dense_vectorBM25 向量一体无需引入新系统十亿级向量高性能要求Milvus分布式存算分离10 种索引算法可选毫秒级延迟中等规模元数据过滤复杂QdrantRust 高性能过滤条件下查询延迟几乎不受影响快速验证/POC/学习ChromaDocker 一条命令Python/Java SDK 随手可用如果你尚不确定未来规模最稳妥的策略是 pgvector起步在 PostgreSQL 上验证如果数据量突破千万且延迟不可接受再迁移到 Milvus——Spring AI 的VectorStore统一接口让迁移只需改依赖和配置业务代码零改动。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
一、向量数据库在 RAG 流程中的位置回顾 RAG 的完整流程向量数据库承担着存储与检索的核心角色将私有知识文档、手册、代码库等分片后通过 Embedding 模型转为向量存入向量数据库。用户提问时将问题同样转为向量。在向量数据库中执行相似性搜索找出与问题语义最接近的 Top-K 个文档块。将检索到的上下文和用户问题一起传给大模型生成有据可依的回答。Spring AI 提供了统一的VectorStore接口屏蔽底层差异官方文档https://docs.spring.io/spring-ai/reference/api/vectordbs.html 列出了所有支持的实现。本文聚焦于可私有化部署的向量数据库排除仅云服务的产品如 Pinecone确保企业敏感数据不离开内部环境。二、选型的六个核心维度向量数据库选型没有最好只有最合适。以下六个维度是评估重点2.1 部署复杂度部署和运维门槛直接影响团队能否快速落地。Chroma可在内存中直接运行适合原型阶段pgvector只需在现有 PostgreSQL 上CREATE EXTENSION vectorMilvus则需要容器化部署和专业运维能力。部署复杂度越高后期投入越大。2.2 检索性能硬指标——查询延迟单次响应速度和吞吐量并发 QPS。多数向量索引常驻内存内存消耗直接决定硬件成本。HNSW 索引查询快但构建慢且内存占用高IVF 索引用内存更少但召回率略低。2.3 可扩展性数据量在百万级以下几乎所有数据库都能胜任。当规模增长到千万甚至亿级时Milvus的分布式存算分离架构优势明显pgvector则受限于 PostgreSQL 单机瓶颈Qdrant提供中等规模的集群能力。2.4 集成便利性与现有技术栈兼容是选型的实用智慧。如果已有 PostgreSQL直接用pgvector零额外组件已有 Elasticsearch 集群直接启用dense_vector字段即可如果团队以 Java/Spring 为主优先看 Spring AI 官方提供 Starter 的产品。2.5 高级特性元数据过滤是生产环境的硬门槛——如果无法按文档来源、版本号、日期等过滤检索结果不可控基本可以排除。混合检索BM25 关键词 向量语义能将两种检索优势互补也是从能用到好用的关键。2.6 社区活跃度活跃的社区意味着持续的 bug 修复、性能优化和丰富的踩坑经验。截至 2025 年Milvus36K GitHub Stars和 pgvector12K Stars生态最为成熟。三、候选数据库详解以下逐一分析可私有化部署的五款主流向量数据库每款均基于 Spring AI 1.0 官方 Starter 给出 Maven 依赖和 YAML 配置示例并使用《仙逆》片段作为演示数据。3.1 PGVector —— 就地取材、SQL 向量合二为一定位PostgreSQL 扩展CREATE EXTENSION vector即可让现有关系型数据库拥有向量能力。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-pgvector/artifactId/dependencydependency groupIdorg.springframework.boot/groupId artifactIdspring-boot-starter-jdbc/artifactId/dependencydependency groupIdorg.postgresql/groupId artifactIdpostgresql/artifactId/dependencyapplication.ymlspring: datasource: url:jdbc: postgresql://localhost:5432/xianni_rag username: postgres password: postgresai: vectorstore: pgvector: index-type: HNSW # HNSW | IVFFLAT distance-type: COSINE_DISTANCE # COSINE_DISTANCE | EUCLIDEAN_DISTANCE | NEGATIVE_INNER_PRODUCT dimensions: 1024 # 须与 Embedding 模型输出维度一致 initialize-schema: true # 首次启动自动建表使用示例——存储并检索《仙逆》片段// 注入 Spring AI 自动配置的 VectorStoreAutowiredprivate VectorStore vectorStore;// 写入将《仙逆》片段写入向量库 ListDocument documents List.of( new Document(王林自封修为在落月村化身木匠陪伴儿子王平七十二年。, Map.of(character, 王林, chapter, 二次化凡)), new Document(雷道子看穿王平的怨婴体质要拿他炼器触碰了王林的逆鳞。, Map.of(character, 雷道子, chapter, 二次化凡)), new Document(司徒南被封印在天逆珠中万年性格豪爽多次危急时出手救王林。, Map.of(character, 司徒南, chapter, 仙罡大陆)), new Document(李慕婉结婴失败身殒残魂被保存在天逆珠中王林耗尽千年将其复活。, Map.of(character, 李慕婉, chapter, 全文主线)));vectorStore.add(documents);// 检索查询王林如何在落月村陪伴儿子 SearchRequest request SearchRequest.builder() .query(王林如何在落月村陪伴儿子) .topK(3) .similarityThreshold(0.7) .filterExpression(character 王林) // 按人物过滤 .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林自封修为在落月村化身木匠陪伴儿子王平七十二年。pgvector 的核心优势在于 SQL 向量的混合查询——你可以写一条 SQL 同时做结构化过滤、全文检索和向量相似度排序这在需要复杂业务逻辑的场景中无可替代-- 查询二次化凡章节中与王平怨气语义最接近的 5 个片段SELECT content, 1 - (embedding query_embedding) AS similarityFROM vector_storeWHERE metadata-chapter 二次化凡 -- 结构化过滤 AND 1 - (embedding query_embedding) 0.7ORDER BY embedding query_embeddingLIMIT 5;  检索结果  **特点总结** | 维度 | 评价 | | --- | --- | | 部署复杂度 | 低——已有 PG 零成本CREATE EXTENSION 搞定 | | 数据规模 | 百万~千万级亿级以上性能下降明显 | | 索引算法 | HNSW、IVFFlat | | 混合检索 | 借助 PG 全文检索 JOIN 灵活组合 | | 元数据过滤 | 完整支持SQL WHERE 级别 | | 适用场景 | 已有 PG 的团队、中小规模 RAG、需要 SQL 混合查询的业务 | | Spring AI Starter | spring-ai-starter-vector-store-pgvector | --- ### 3.2 Chroma —— 轻量级 AI 原生数据库 **定位**专为 AI 应用设计的轻量向量数据库开箱即用甚至可在内存中运行。 **Maven 依赖** plaintext dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-chroma/artifactId/dependencyapplication.ymlspring: ai: vectorstore: chroma: host: http://localhost:8000 # Chroma 服务地址 collection-name: xianni_knowledge # 集合名称 initialize-schema: true使用示例——用 Chroma 管理《仙逆》人物档案Autowiredprivate VectorStore vectorStore;// 写入《仙逆》人物卡片ListDocument characters List.of( new Document(王林主角资质平平但心智坚韧。顺为凡逆则仙为信念从恒岳派杂役修至踏天之境。, Map.of(type, character_card, importance, main)), new Document(王平养子天生怨婴体质。王林为化解他的怨气自封修为在落月村陪伴他七十二年。, Map.of(type, character_card, importance, key)), new Document(雷道子阴虚境强者看穿王平怨婴真相要拿他炼器被王林以问鼎中期修为越级斩杀。, Map.of(type, character_card, importance, minor)));vectorStore.add(characters);// 搜索——用户问王林自封修为是为了谁ListDocument results vectorStore.similaritySearch( SearchRequest.builder() .query(王林自封修为是为了谁) .topK(2) .build());// 命中王平的人物卡片——王林为化解他的怨气自封修为特点总结维度评价部署复杂度极低——Docker 一行命令支持嵌入/CS 两种模式数据规模小规模十万~百万级不适用高并发生产索引算法HNSW默认混合检索不支持原生混合检索元数据过滤简单支持适用场景原型验证、教学实验、个人项目。生产环境不推荐Spring AI Starterspring-ai-starter-vector-store-chroma3.3 Milvus —— 大规模生产的分布式方案定位云原生分布式向量数据库为十亿级向量检索而生是开源方案中最成熟的专业产品。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-milvus/artifactId/dependencyapplication.ymlspring: ai: vectorstore: milvus: host: localhost port: 19530 database-name: default collection-name: xianni_full_text metric-type: COSINE # COSINE | L2 | IP index-type: IVF_FLAT # IVF_FLAT | HNSW | IVF_SQ8 | IVF_PQ 等 dimensions: 1024 initialize-schema: true使用示例——《仙逆》全量小说检索Autowiredprivate VectorStore vectorStore;// 写入整部《仙逆》的分片示意实际可能是数万个分片ListDocument chapters List.of( new Document(化神先化凡这是化神期的关键一步。他低头看了看自己的双手 这双手曾经沾满鲜血如今却只是在木雕上刻下纹路。, Map.of(volume, 化凡篇, chapter_num, 342)), new Document(王平临终前握住王林的手用最后的力气问爹我到底能不能修道 王林老泪纵横不能……平儿不是爹不让你修……是你修不了啊……, Map.of(volume, 二次化凡, chapter_num, 367)), new Document(王林仰天长笑道心从生死意境蜕变为因果意境。 为后续跳过阴虚阳实、直入窥涅铺平了道路。, Map.of(volume, 二次化凡, chapter_num, 370)));vectorStore.add(chapters);// 检索——用户问王林是怎么悟出因果意境的SearchRequest request SearchRequest.builder() .query(王林是怎么悟出因果意境的) .topK(5) .similarityThreshold(0.75) .filterExpression(volume 二次化凡) .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林在落月村陪伴王平→王平去世→道心蜕变→因果意境 的完整因果链Milvus 检索示例假设《仙逆》全量有 40 万个分片查询因果意境如何悟出Milvus 在 IVF_FLAT 索引下仅需扫描约 5% 的聚类2 万个向量延迟控制在毫秒级。同查询在 pgvector 上如果做到亿级数据量延迟将明显上升。特点总结维度评价部署复杂度高——需容器化Docker Compose/K8s推荐 16GB 内存数据规模十亿级水平扩展索引算法10 种HNSW, IVF_FLAT, IVF_SQ8, IVF_PQ, DiskANN, GPU 加速等混合检索原生支持v2.5 密集向量 BM25 稀疏向量 全文检索元数据过滤完整支持标量索引加速适用场景大规模企业 RAG、推荐系统、图像/视频语义搜索Spring AI Starterspring-ai-starter-vector-store-milvus3.4 Qdrant —— 性能与简洁的平衡定位Rust 实现的高性能向量数据库API 简洁内存效率高兼顾性能与易用性。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-qdrant/artifactId/dependencyapplication.ymlspring: ai: vectorstore: qdrant: host: localhost port: 6334 collection-name: xianni_rag initialize-schema: true使用示例——用 Qdrant 的元数据过滤做精准检索Autowiredprivate VectorStore vectorStore;// 写入《仙逆》战斗场景数据ListDocument battles List.of( new Document(王林以问鼎中期修为迎战阴虚境雷道子。因果意境锁定魂魄 射神车轮转碾碎空间一击斩杀。, Map.of(battle_type, 越级战, winner, 王林, loser, 雷道子)), new Document(司徒南破开天逆珠封印一剑斩灭三位窥涅期修士的联手围杀。, Map.of(battle_type, 碾压局, winner, 司徒南, loser, 窥涅三人组)), new Document(清水仙君在洞府大战中以一敌百剑下无一合之敌。, Map.of(battle_type, 群战, winner, 清水, loser, 洞府联军)));vectorStore.add(battles);// 检索——用户问王林打过的越级战有哪些SearchRequest request SearchRequest.builder() .query(王林打过的越级战有哪些) .topK(5) .filterExpression(winner 王林 battle_type 越级战) .build();ListDocument results vectorStore.similaritySearch(request);// Qdrant 的元数据过滤性能极高——在过滤条件下仍然保持低延迟检索特点总结维度评价部署复杂度中——Docker 单命令Rust 实现资源占用低数据规模中等百万~千万级多节点集群支持索引算法HNSW 为主支持标量/向量量化压缩混合检索稀疏密集向量组合元数据过滤高性能——过滤条件下查询性能下降很小核心优势适用场景中等规模、需要复杂元数据过滤、追求简洁运维的团队Spring AI Starterspring-ai-starter-vector-store-qdrant3.5 Elasticsearch —— 关键词 向量的万能选手定位搜索引擎出身8.0 版本支持dense_vector字段擅长全文检索与向量检索的融合。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-elasticsearch/artifactId/dependencyapplication.ymlspring: elasticsearch: uris: http://localhost:9200ai: vectorstore: elasticsearch: index-name: xianni_rag dimensions: 1024 similarity: cosine # cosine | l2_norm | dot_product initialize-schema: true使用示例——全文 向量混合搜索《仙逆》Autowiredprivate VectorStore vectorStore;// 写入《仙逆》高光片段ListDocument highlights List.of( new Document(顺为凡逆则仙。王林以此信念走过了千年修真路 从恒岳派的杂役做到了一界之主再到踏天。 Map.of(type, 名言, speaker, 旁白)), new Document(王平三次问父亲能不能修道三次被拒绝。 这不是残忍是保护——怨婴一旦修仙怨气爆发便魂飞魄散。 Map.of(type, 名场面, chapter, 王平三问)), new Document(雷道子道破真相那日王林解开封印。问鼎中期的气势如火山爆发 万古枯木从地底破土射神车碾碎虚空。 Map.of(type, 战斗, chapter, 落月村之战)));vectorStore.add(highlights);// Elasticsearch 优势——在 query 中混合关键词匹配 语义相似度// 用户搜索落月村 战斗——落月村命中 BM25战斗命中语义向量SearchRequest request SearchRequest.builder() .query(落月村发生的战斗) .topK(3) .build();ListDocument results vectorStore.similaritySearch(request);// ES 在同一查询中融合 BM25 关键词匹配 向量语义精准定位雷道子之战特点总结维度评价部署复杂度中偏高——JVM 调优、集群管理需经验数据规模中等百万~十亿级依赖 ES 集群扩展索引算法HNSWdense_vector字段混合检索核心优势——原生融合 BM25 向量scoreα×BM25 (1-α)×余弦元数据过滤完整支持倒排索引加持适用场景已有 ELK 的团队、需关键词语义双引擎的场景Spring AI Starterspring-ai-starter-vector-store-elasticsearch四、全方位对比维度PGVectorChromaMilvusQdrantElasticsearch定位PG 扩展轻量 AI 原生分布式专业库高性能简洁搜索引擎向量部署复杂度低极低高中中偏高数据规模百万~千万十万~百万十亿级百万~千万百万~十亿索引算法HNSW, IVFFlatHNSW10 种含 GPUHNSWHNSW混合检索SQL 组合不支持原生部分原生最大优势元数据过滤完整简单完整高性能完整Spring AI StarterpgvectorchromamilvusqdrantelasticsearchLangChain4j 模块langchain4j-pgvectorlangchain4j-chromalangchain4j-milvuslangchain4j-qdrantlangchain4j-elasticsearch适用场景已有PG的中小RAG原型/学习大规模生产中等规模已有ES的混合搜索五、选型决策以下按团队现状给出推荐路径你的情况推荐理由已有 PostgreSQL百万级文档pgvector零新组件SQL JOIN 关联元数据和父块运维零成本已有 Elasticsearch 集群Elasticsearch就地启用dense_vectorBM25 向量一体无需引入新系统十亿级向量高性能要求Milvus分布式存算分离10 种索引算法可选毫秒级延迟中等规模元数据过滤复杂QdrantRust 高性能过滤条件下查询延迟几乎不受影响快速验证/POC/学习ChromaDocker 一条命令Python/Java SDK 随手可用如果你尚不确定未来规模最稳妥的策略是 pgvector起步在 PostgreSQL 上验证如果数据量突破千万且延迟不可接受再迁移到 Milvus——Spring AI 的VectorStore统一接口让迁移只需改依赖和配置业务代码零改动。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
向量数据库如何选型?
发布时间:2026/5/29 3:31:19
一、向量数据库在 RAG 流程中的位置回顾 RAG 的完整流程向量数据库承担着存储与检索的核心角色将私有知识文档、手册、代码库等分片后通过 Embedding 模型转为向量存入向量数据库。用户提问时将问题同样转为向量。在向量数据库中执行相似性搜索找出与问题语义最接近的 Top-K 个文档块。将检索到的上下文和用户问题一起传给大模型生成有据可依的回答。Spring AI 提供了统一的VectorStore接口屏蔽底层差异官方文档https://docs.spring.io/spring-ai/reference/api/vectordbs.html 列出了所有支持的实现。本文聚焦于可私有化部署的向量数据库排除仅云服务的产品如 Pinecone确保企业敏感数据不离开内部环境。二、选型的六个核心维度向量数据库选型没有最好只有最合适。以下六个维度是评估重点2.1 部署复杂度部署和运维门槛直接影响团队能否快速落地。Chroma可在内存中直接运行适合原型阶段pgvector只需在现有 PostgreSQL 上CREATE EXTENSION vectorMilvus则需要容器化部署和专业运维能力。部署复杂度越高后期投入越大。2.2 检索性能硬指标——查询延迟单次响应速度和吞吐量并发 QPS。多数向量索引常驻内存内存消耗直接决定硬件成本。HNSW 索引查询快但构建慢且内存占用高IVF 索引用内存更少但召回率略低。2.3 可扩展性数据量在百万级以下几乎所有数据库都能胜任。当规模增长到千万甚至亿级时Milvus的分布式存算分离架构优势明显pgvector则受限于 PostgreSQL 单机瓶颈Qdrant提供中等规模的集群能力。2.4 集成便利性与现有技术栈兼容是选型的实用智慧。如果已有 PostgreSQL直接用pgvector零额外组件已有 Elasticsearch 集群直接启用dense_vector字段即可如果团队以 Java/Spring 为主优先看 Spring AI 官方提供 Starter 的产品。2.5 高级特性元数据过滤是生产环境的硬门槛——如果无法按文档来源、版本号、日期等过滤检索结果不可控基本可以排除。混合检索BM25 关键词 向量语义能将两种检索优势互补也是从能用到好用的关键。2.6 社区活跃度活跃的社区意味着持续的 bug 修复、性能优化和丰富的踩坑经验。截至 2025 年Milvus36K GitHub Stars和 pgvector12K Stars生态最为成熟。三、候选数据库详解以下逐一分析可私有化部署的五款主流向量数据库每款均基于 Spring AI 1.0 官方 Starter 给出 Maven 依赖和 YAML 配置示例并使用《仙逆》片段作为演示数据。3.1 PGVector —— 就地取材、SQL 向量合二为一定位PostgreSQL 扩展CREATE EXTENSION vector即可让现有关系型数据库拥有向量能力。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-pgvector/artifactId/dependencydependency groupIdorg.springframework.boot/groupId artifactIdspring-boot-starter-jdbc/artifactId/dependencydependency groupIdorg.postgresql/groupId artifactIdpostgresql/artifactId/dependencyapplication.ymlspring: datasource: url:jdbc: postgresql://localhost:5432/xianni_rag username: postgres password: postgresai: vectorstore: pgvector: index-type: HNSW # HNSW | IVFFLAT distance-type: COSINE_DISTANCE # COSINE_DISTANCE | EUCLIDEAN_DISTANCE | NEGATIVE_INNER_PRODUCT dimensions: 1024 # 须与 Embedding 模型输出维度一致 initialize-schema: true # 首次启动自动建表使用示例——存储并检索《仙逆》片段// 注入 Spring AI 自动配置的 VectorStoreAutowiredprivate VectorStore vectorStore;// 写入将《仙逆》片段写入向量库 ListDocument documents List.of( new Document(王林自封修为在落月村化身木匠陪伴儿子王平七十二年。, Map.of(character, 王林, chapter, 二次化凡)), new Document(雷道子看穿王平的怨婴体质要拿他炼器触碰了王林的逆鳞。, Map.of(character, 雷道子, chapter, 二次化凡)), new Document(司徒南被封印在天逆珠中万年性格豪爽多次危急时出手救王林。, Map.of(character, 司徒南, chapter, 仙罡大陆)), new Document(李慕婉结婴失败身殒残魂被保存在天逆珠中王林耗尽千年将其复活。, Map.of(character, 李慕婉, chapter, 全文主线)));vectorStore.add(documents);// 检索查询王林如何在落月村陪伴儿子 SearchRequest request SearchRequest.builder() .query(王林如何在落月村陪伴儿子) .topK(3) .similarityThreshold(0.7) .filterExpression(character 王林) // 按人物过滤 .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林自封修为在落月村化身木匠陪伴儿子王平七十二年。pgvector 的核心优势在于 SQL 向量的混合查询——你可以写一条 SQL 同时做结构化过滤、全文检索和向量相似度排序这在需要复杂业务逻辑的场景中无可替代-- 查询二次化凡章节中与王平怨气语义最接近的 5 个片段SELECT content, 1 - (embedding query_embedding) AS similarityFROM vector_storeWHERE metadata-chapter 二次化凡 -- 结构化过滤 AND 1 - (embedding query_embedding) 0.7ORDER BY embedding query_embeddingLIMIT 5;  检索结果  **特点总结** | 维度 | 评价 | | --- | --- | | 部署复杂度 | 低——已有 PG 零成本CREATE EXTENSION 搞定 | | 数据规模 | 百万~千万级亿级以上性能下降明显 | | 索引算法 | HNSW、IVFFlat | | 混合检索 | 借助 PG 全文检索 JOIN 灵活组合 | | 元数据过滤 | 完整支持SQL WHERE 级别 | | 适用场景 | 已有 PG 的团队、中小规模 RAG、需要 SQL 混合查询的业务 | | Spring AI Starter | spring-ai-starter-vector-store-pgvector | --- ### 3.2 Chroma —— 轻量级 AI 原生数据库 **定位**专为 AI 应用设计的轻量向量数据库开箱即用甚至可在内存中运行。 **Maven 依赖** plaintext dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-chroma/artifactId/dependencyapplication.ymlspring: ai: vectorstore: chroma: host: http://localhost:8000 # Chroma 服务地址 collection-name: xianni_knowledge # 集合名称 initialize-schema: true使用示例——用 Chroma 管理《仙逆》人物档案Autowiredprivate VectorStore vectorStore;// 写入《仙逆》人物卡片ListDocument characters List.of( new Document(王林主角资质平平但心智坚韧。顺为凡逆则仙为信念从恒岳派杂役修至踏天之境。, Map.of(type, character_card, importance, main)), new Document(王平养子天生怨婴体质。王林为化解他的怨气自封修为在落月村陪伴他七十二年。, Map.of(type, character_card, importance, key)), new Document(雷道子阴虚境强者看穿王平怨婴真相要拿他炼器被王林以问鼎中期修为越级斩杀。, Map.of(type, character_card, importance, minor)));vectorStore.add(characters);// 搜索——用户问王林自封修为是为了谁ListDocument results vectorStore.similaritySearch( SearchRequest.builder() .query(王林自封修为是为了谁) .topK(2) .build());// 命中王平的人物卡片——王林为化解他的怨气自封修为特点总结维度评价部署复杂度极低——Docker 一行命令支持嵌入/CS 两种模式数据规模小规模十万~百万级不适用高并发生产索引算法HNSW默认混合检索不支持原生混合检索元数据过滤简单支持适用场景原型验证、教学实验、个人项目。生产环境不推荐Spring AI Starterspring-ai-starter-vector-store-chroma3.3 Milvus —— 大规模生产的分布式方案定位云原生分布式向量数据库为十亿级向量检索而生是开源方案中最成熟的专业产品。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-milvus/artifactId/dependencyapplication.ymlspring: ai: vectorstore: milvus: host: localhost port: 19530 database-name: default collection-name: xianni_full_text metric-type: COSINE # COSINE | L2 | IP index-type: IVF_FLAT # IVF_FLAT | HNSW | IVF_SQ8 | IVF_PQ 等 dimensions: 1024 initialize-schema: true使用示例——《仙逆》全量小说检索Autowiredprivate VectorStore vectorStore;// 写入整部《仙逆》的分片示意实际可能是数万个分片ListDocument chapters List.of( new Document(化神先化凡这是化神期的关键一步。他低头看了看自己的双手 这双手曾经沾满鲜血如今却只是在木雕上刻下纹路。, Map.of(volume, 化凡篇, chapter_num, 342)), new Document(王平临终前握住王林的手用最后的力气问爹我到底能不能修道 王林老泪纵横不能……平儿不是爹不让你修……是你修不了啊……, Map.of(volume, 二次化凡, chapter_num, 367)), new Document(王林仰天长笑道心从生死意境蜕变为因果意境。 为后续跳过阴虚阳实、直入窥涅铺平了道路。, Map.of(volume, 二次化凡, chapter_num, 370)));vectorStore.add(chapters);// 检索——用户问王林是怎么悟出因果意境的SearchRequest request SearchRequest.builder() .query(王林是怎么悟出因果意境的) .topK(5) .similarityThreshold(0.75) .filterExpression(volume 二次化凡) .build();ListDocument results vectorStore.similaritySearch(request);// 命中王林在落月村陪伴王平→王平去世→道心蜕变→因果意境 的完整因果链Milvus 检索示例假设《仙逆》全量有 40 万个分片查询因果意境如何悟出Milvus 在 IVF_FLAT 索引下仅需扫描约 5% 的聚类2 万个向量延迟控制在毫秒级。同查询在 pgvector 上如果做到亿级数据量延迟将明显上升。特点总结维度评价部署复杂度高——需容器化Docker Compose/K8s推荐 16GB 内存数据规模十亿级水平扩展索引算法10 种HNSW, IVF_FLAT, IVF_SQ8, IVF_PQ, DiskANN, GPU 加速等混合检索原生支持v2.5 密集向量 BM25 稀疏向量 全文检索元数据过滤完整支持标量索引加速适用场景大规模企业 RAG、推荐系统、图像/视频语义搜索Spring AI Starterspring-ai-starter-vector-store-milvus3.4 Qdrant —— 性能与简洁的平衡定位Rust 实现的高性能向量数据库API 简洁内存效率高兼顾性能与易用性。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-qdrant/artifactId/dependencyapplication.ymlspring: ai: vectorstore: qdrant: host: localhost port: 6334 collection-name: xianni_rag initialize-schema: true使用示例——用 Qdrant 的元数据过滤做精准检索Autowiredprivate VectorStore vectorStore;// 写入《仙逆》战斗场景数据ListDocument battles List.of( new Document(王林以问鼎中期修为迎战阴虚境雷道子。因果意境锁定魂魄 射神车轮转碾碎空间一击斩杀。, Map.of(battle_type, 越级战, winner, 王林, loser, 雷道子)), new Document(司徒南破开天逆珠封印一剑斩灭三位窥涅期修士的联手围杀。, Map.of(battle_type, 碾压局, winner, 司徒南, loser, 窥涅三人组)), new Document(清水仙君在洞府大战中以一敌百剑下无一合之敌。, Map.of(battle_type, 群战, winner, 清水, loser, 洞府联军)));vectorStore.add(battles);// 检索——用户问王林打过的越级战有哪些SearchRequest request SearchRequest.builder() .query(王林打过的越级战有哪些) .topK(5) .filterExpression(winner 王林 battle_type 越级战) .build();ListDocument results vectorStore.similaritySearch(request);// Qdrant 的元数据过滤性能极高——在过滤条件下仍然保持低延迟检索特点总结维度评价部署复杂度中——Docker 单命令Rust 实现资源占用低数据规模中等百万~千万级多节点集群支持索引算法HNSW 为主支持标量/向量量化压缩混合检索稀疏密集向量组合元数据过滤高性能——过滤条件下查询性能下降很小核心优势适用场景中等规模、需要复杂元数据过滤、追求简洁运维的团队Spring AI Starterspring-ai-starter-vector-store-qdrant3.5 Elasticsearch —— 关键词 向量的万能选手定位搜索引擎出身8.0 版本支持dense_vector字段擅长全文检索与向量检索的融合。Maven 依赖dependency groupIdorg.springframework.ai/groupId artifactIdspring-ai-starter-vector-store-elasticsearch/artifactId/dependencyapplication.ymlspring: elasticsearch: uris: http://localhost:9200ai: vectorstore: elasticsearch: index-name: xianni_rag dimensions: 1024 similarity: cosine # cosine | l2_norm | dot_product initialize-schema: true使用示例——全文 向量混合搜索《仙逆》Autowiredprivate VectorStore vectorStore;// 写入《仙逆》高光片段ListDocument highlights List.of( new Document(顺为凡逆则仙。王林以此信念走过了千年修真路 从恒岳派的杂役做到了一界之主再到踏天。 Map.of(type, 名言, speaker, 旁白)), new Document(王平三次问父亲能不能修道三次被拒绝。 这不是残忍是保护——怨婴一旦修仙怨气爆发便魂飞魄散。 Map.of(type, 名场面, chapter, 王平三问)), new Document(雷道子道破真相那日王林解开封印。问鼎中期的气势如火山爆发 万古枯木从地底破土射神车碾碎虚空。 Map.of(type, 战斗, chapter, 落月村之战)));vectorStore.add(highlights);// Elasticsearch 优势——在 query 中混合关键词匹配 语义相似度// 用户搜索落月村 战斗——落月村命中 BM25战斗命中语义向量SearchRequest request SearchRequest.builder() .query(落月村发生的战斗) .topK(3) .build();ListDocument results vectorStore.similaritySearch(request);// ES 在同一查询中融合 BM25 关键词匹配 向量语义精准定位雷道子之战特点总结维度评价部署复杂度中偏高——JVM 调优、集群管理需经验数据规模中等百万~十亿级依赖 ES 集群扩展索引算法HNSWdense_vector字段混合检索核心优势——原生融合 BM25 向量scoreα×BM25 (1-α)×余弦元数据过滤完整支持倒排索引加持适用场景已有 ELK 的团队、需关键词语义双引擎的场景Spring AI Starterspring-ai-starter-vector-store-elasticsearch四、全方位对比维度PGVectorChromaMilvusQdrantElasticsearch定位PG 扩展轻量 AI 原生分布式专业库高性能简洁搜索引擎向量部署复杂度低极低高中中偏高数据规模百万~千万十万~百万十亿级百万~千万百万~十亿索引算法HNSW, IVFFlatHNSW10 种含 GPUHNSWHNSW混合检索SQL 组合不支持原生部分原生最大优势元数据过滤完整简单完整高性能完整Spring AI StarterpgvectorchromamilvusqdrantelasticsearchLangChain4j 模块langchain4j-pgvectorlangchain4j-chromalangchain4j-milvuslangchain4j-qdrantlangchain4j-elasticsearch适用场景已有PG的中小RAG原型/学习大规模生产中等规模已有ES的混合搜索五、选型决策以下按团队现状给出推荐路径你的情况推荐理由已有 PostgreSQL百万级文档pgvector零新组件SQL JOIN 关联元数据和父块运维零成本已有 Elasticsearch 集群Elasticsearch就地启用dense_vectorBM25 向量一体无需引入新系统十亿级向量高性能要求Milvus分布式存算分离10 种索引算法可选毫秒级延迟中等规模元数据过滤复杂QdrantRust 高性能过滤条件下查询延迟几乎不受影响快速验证/POC/学习ChromaDocker 一条命令Python/Java SDK 随手可用如果你尚不确定未来规模最稳妥的策略是 pgvector起步在 PostgreSQL 上验证如果数据量突破千万且延迟不可接受再迁移到 Milvus——Spring AI 的VectorStore统一接口让迁移只需改依赖和配置业务代码零改动。学AI大模型的正确顺序千万不要搞错了2026年AI风口已来各行各业的AI渗透肉眼可见超多公司要么转型做AI相关产品要么高薪挖AI技术人才机遇直接摆在眼前有往AI方向发展或者本身有后端编程基础的朋友直接冲AI大模型应用开发转岗超合适就算暂时不打算转岗了解大模型、RAG、Prompt、Agent这些热门概念能上手做简单项目也绝对是求职加分王给大家整理了超全最新的AI大模型应用开发学习清单和资料手把手帮你快速入门学习路线:✅大模型基础认知—大模型核心原理、发展历程、主流模型GPT、文心一言等特点解析✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑✅开发基础能力—Python进阶、API接口调用、大模型开发框架LangChain等实操✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经以上6大模块看似清晰好上手实则每个部分都有扎实的核心内容需要吃透我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


)



)


)


:测试如何提前在代码提交阶段发现 Bug?)


)

